






处理器和GPU的计算能力如何计算的?
(一) CPU的浮点计算性能公式
我们常用双精度浮点运算能力衡量一个处理器的科学计算的能力,就是处理64bit小数点浮动数据的能力
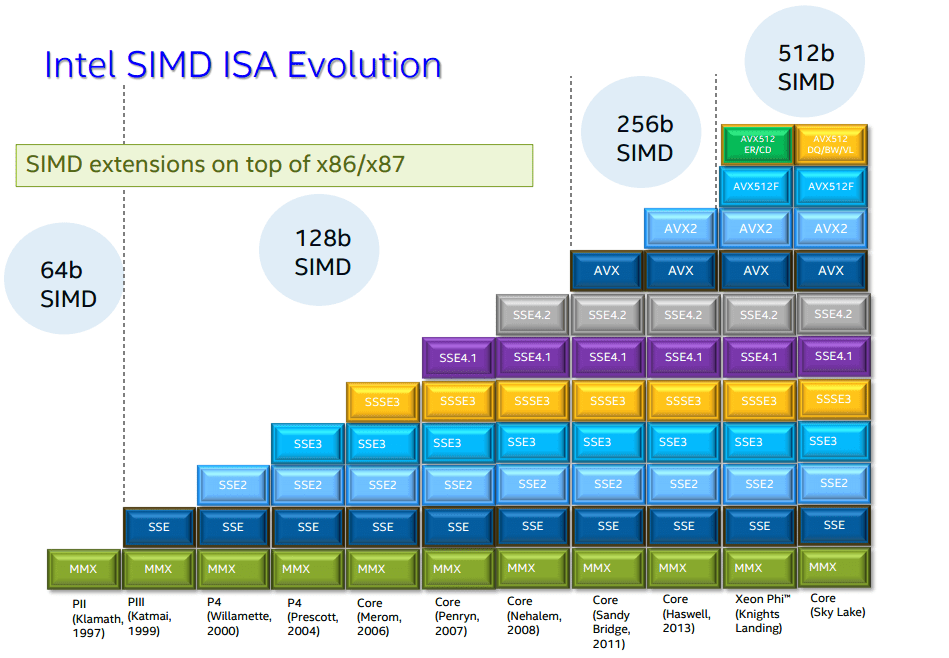
intel的最新cpu支持高级矢量指令集AVX2、AVX512, 其中AVX2的处理器的单指令的长度是256bit,每颗intelCPU包含2个FMA,一个FMA一个时钟周期可以进行2次乘或者加的运算,那么这个处理器在1个核心1个时钟周期可以执行256bit*2FMA*2M/A/64=16次浮点运算,也称为16FLOPs,就是Floating Point Operations Per Second;
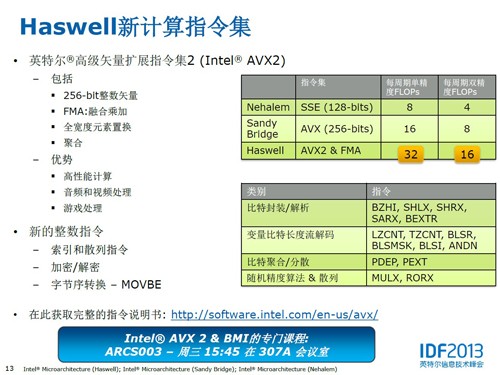
支持AVX512的处理器的单指令的长度是512Bit,每个intel核心假设包含2个FMA,一个FMA一个时钟周期可以进行2次乘或者加的运算,那么这个处理器在1个核心1个时钟周期可以执行512bit*2FMA*2M/A/64=32次浮点运算,也称为32FLOPs,
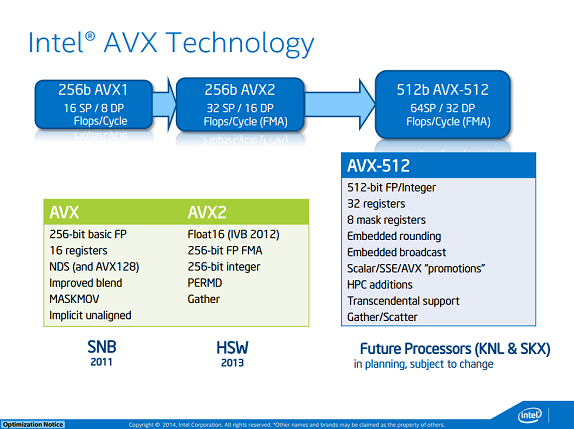
就是说理论上后者的运算能力其实是前者的一倍,但是实际中不可能达到,因为进行更长的指令运算,流水线之间更加密集,但核心频率会降低;导致整个处理器的能力降低;
一个处理器的计算能力和核心的个数,核心的频率,核心单时钟周期的能力三个因素有关系
例如:现在intel purley platform的旗舰skylake 8180是28Core@2.5GHZ,支持AVX512,其理论双精度浮点性能是:28Core*2.5GHZ*32FLOPs/Cycle=2240GFLPs=2.24TFLOPs
例如:现在intel purley platform的旗舰cascade lake Xeon Platinum 8280是28核@2.7GHZ,支持AVX512,其理论双精度浮点性能是:28Core*2.7GHZ*32FLOPs/Cycle=2419.2GFLPs=2.4192TFLOPs
但是还是要注意并不是所有的处理器都有支持AVX512的指令集,也并不是每个支持处理器都有2个FMA的运算单元。
(二) GPU的浮点性能计算公式
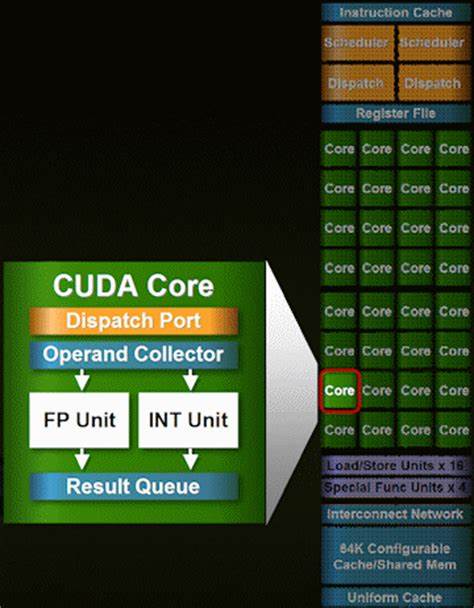
GPU能做的CPU都能做,CPU能做的GPU却不一定能够做到,GPU一般一个时钟周期可以操作64bit的数据,1个核心实现1个FMA。
这个GPU的计算能力的单元是:64bit*1FMA*2M/A/64bit=2FLOPs/Cycle
GPU的计算能力也是一样和核心个数,核心频率,核心单时钟周期能力三个因素有关。
但是架不住GPU的核心的数量多呀
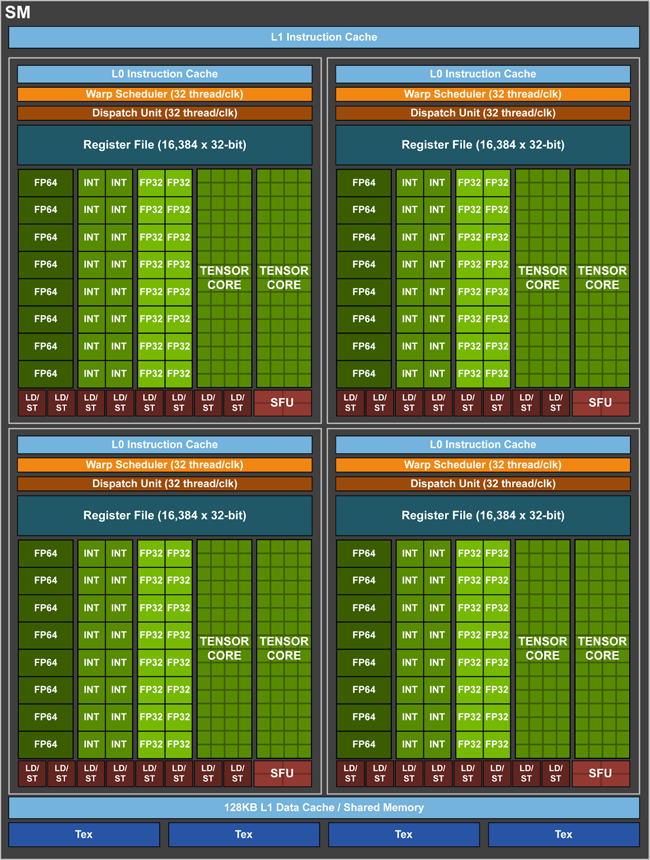
例如:对现在nvidia 的pascal架构超算卡--- Tesla P100,是1792核@1.328GHz,其理论的双精度浮点性能是:1792Core*1.328GHZ*2FLOPs/Cycle=4759.552GFLOPs=4.7TFLOPs
例如:对现在nvidia 的Volta架构的超算卡---Tesla V100,是2560核@1.245GHz,其理论的双精度浮点性能是:2560Core*1.245GHZ*2FLOPs/Cycle=6374.4GFLOPs=6.3TFLOPs
现在ML繁荣的时代,对64bit长度的浮点运算需求不是那么的大,反而是32bit或者16bit、8bit INT、4bit INT的运算需求比较大。
因此nvidia 最新的tesla一直在强调单精度甚至半精度,turing就是这样的。
intel为了加速这些计算,也在其处理器中实现了一些加速低精度运算的指令。


