AMD“推土机”和Intel Xeon 5600以及 Xeon E7性能评测对比
AMD新一代处理器架构Bulldozer(推土机)在两年前就已经引起业界的广泛注意,由于其新颖的“物理双线程”设计让很多人对于AMD首次涉足多线程领域的表现非常期待。2009年11月11日,AMD正式明确了Bulldozer的架构,而随着日后Bulldozer的细节公布,本站也做了相应的报道,其双核模块的设计确实让人眼前一亮,好奇心也因此更上一层楼。近日,桌面版的Bulldozer处理器率先亮相,8核心的FX8100与4核心的FX4100的评测已经铺天盖地,而11月14日,面向企业级应用市场的皓龙(Opteron)版Bulldozer终于正式亮相,分别是最高16核心/8模块的Opteron 6200系列与最高8核心/4模块的Opteron 4200系列。由此也正式向世人宣布了AMD的最新服务器平台。在AMD的声明中强调,新一代基于Bulldozer的皓龙处理器将为云时代提供强大的动力,同时也为企业带来高效、节能的基础运算平台。那么从理论到实践,从期盼到现实,Bulldozer能为将来的云“推”出多大 的天空任其驰骋呢?我们今天就来做一分析,而重点就是Opteron 6200系列。
Opteron 6200处理器新特性简介
有关Bulldozer处理器架构的介绍,已经有很多了,但为了文章的完整性,我们今天也在此做一简单的回顾与介绍(参见上面提到的本站专文),首先要明确的是,从Bulldozer开始,传统意义上的“CPU核心”的概念已经有了变化。
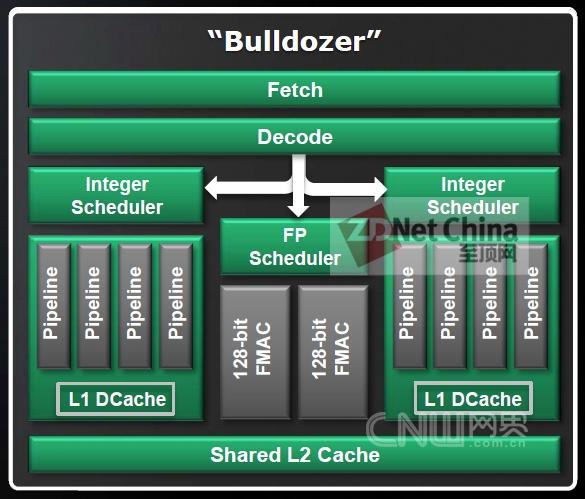
Bulldozer的“模块”架构图,可以看作是两个整数处理核心共享一个浮点处理单元的设计 ,因为日常的处理运算中,更多的是整数处理,所以这就变向的等于在一个模块可以同时处理两个整数处理线程,而无需共享处理管线
AMD当初开发Bulldozer架构的初衷在于,经调查发现日常的IT应用主要集中于整数运算,而浮点运算相对较少。为了提高多线程处理的性能,AMD设想可不可以用2+1的方式来解决,即两个整数处理核心+1个浮点处理单元,以组成一个新架构的处理单元——Module(模块)。 众所周知,在多线程处理方面,英特尔最早提出了Hyper-Threading(超线程)的理念,可以使操作系统或者应用软件的多个线程,同时运行于一个超线程处理器上,其内部的两个逻辑处理器共享一组处理器执行单元。而AMD CPU的两个线程使用各自的单元,但两个线程是共享命令解码器和浮点运算等资源的。因为是整数运算,所有线程之间没有冲突,因此吞吐量有所提高。

从芯片级别看Bulldozer模块,每个模块拥有自己的L2缓存,L3缓存则为晶片级共享
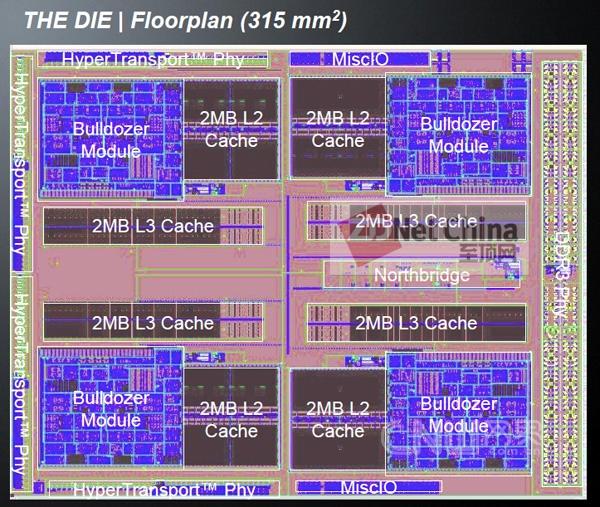
Opteron 6200与4200的晶片设计图,4200由单晶片(功能单元略有不同)构成,最多4个模块(8核心),6200由两块该晶片组成,最多8个模块(16个核心)
由于这种2+1的核心设计,在Bulldozer的架构中,其核心(Core)的概念已经与传统认识有了较大的不同,单一的核心并不是一个具备完整功能的处理单位,所以AMD一直在用Bulldozer Module来表示Bulldozer处理器的处理单元,所以在后文的介绍中,对于Opteron 6200我们也将用模块和核心两个概念表述——在这里,核心是指组成模块中的整数处理单元,它们共享一个弹性浮点处理单元(Flex FP)。
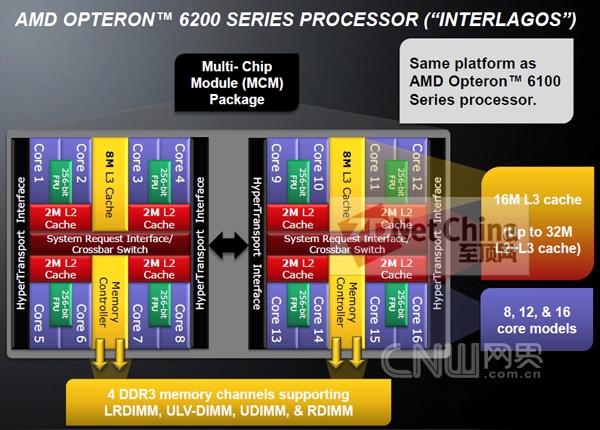
Opteron 6200的内部架构图,相当于用两块4200组成,两个芯片之间由HyperTransport总线互联
在Bulldozer架构中,非常值得一提的是由两个整数处理核心共享的Flex FP处理单元与新增加的独家指令集。这一Flex FP由两个128bit FMAC(Fused Multiply–Add Capability,混合乘加)处理单元组成,之所以称为弹性(Flex),是因为这两个单元可以各自独立,为每个整数核心提供独享的128bit浮点处理单元(此时可以认为是两个具备有整数运算+128bit浮点运算单元的处理核心,组成了Bulldozer Module),也可以组合成一个256bit的浮点处理单元为一个模块提供服务,这其实给编程人员提供了很好的弹性,但也预示着对现有的应用需要进一步的优化。 #p#page_title#e#
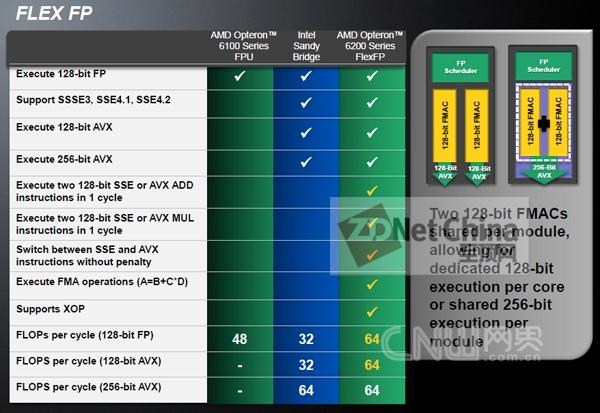
Opteron 6200与6100、英特尔的SandyBridge之间的浮点处理模式的对比
简单来说,这种两个128bit单元弹性组合的方式,提供了有多种指令处理的模式,比如对于同时执行两个128bit的AVX指令,SandyBridge单一的256bit FP单元就不行了,而Flex FP则可以,同样的,这也适用于SSE指令。所以,AMD强调,除非是256bit的AVX指令环境,否则6200的单周期浮点处理能力是SandyBridge的两倍,显然灵活的可分拆也可组合的Flex FP功不可没。
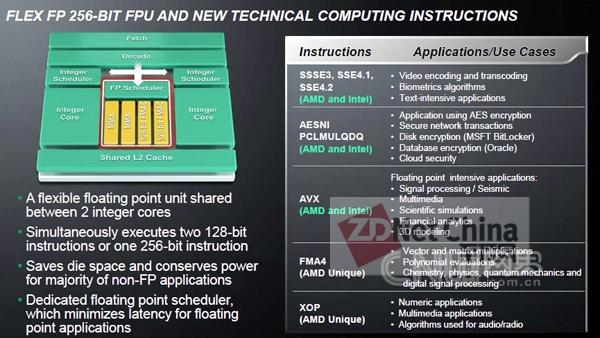
Opteron 6200除了具备与英特尔SandyBridge相同的指令集外,还独家提供了两套指令集
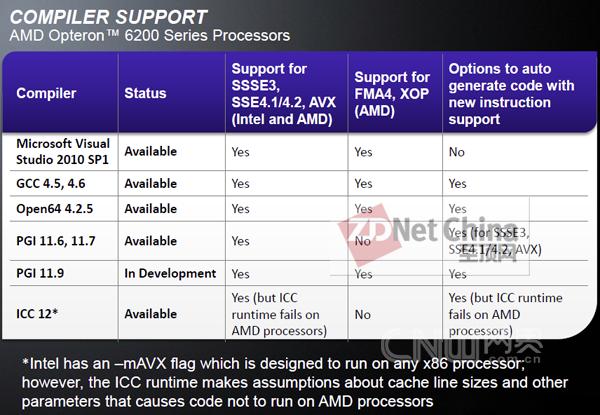
目前主流的编译器大多已经支持AMD的FMA4和XOP指令集
而为了发挥Flex FP的强大的威力,AMD也专门开发了两套针对浮点运算的指令集FMA4与XOP,两者可以说都是为高性能计算所服务,但侧重点不太相同,FMA4更有针对性,比如向量和矩阵计算、多项式评估、数据信号处理等,而XOP则针对数学、多媒体应用等。目前,主流的编译器大多已经全部或部分支持AMD的新指令集,因此在发挥Bulldozer的浮点威力方面,还是很让人期待的。

新一代Opteron 6200/4200的主要特性
说完主要的处理架构的亮点外,我们再来看看其他方面的改。AMD强调了新一代处理器在三个方面的灵活性优势,分别是处理性能的灵活性,能耗的灵活性与平台及虚拟化的灵活性。而相较上一代的6100处理器平台,我认为前两者的改进最为明显。
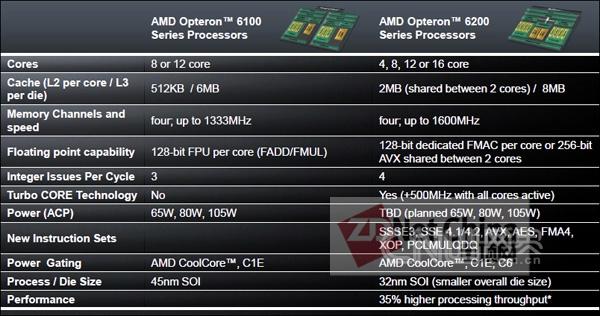
Opteron 6200与6100对比,请注意整数处理的每周期发射数的提高(预示整数性能提升更明显)、Turbo CORE超频、C6能耗控制等新的变化
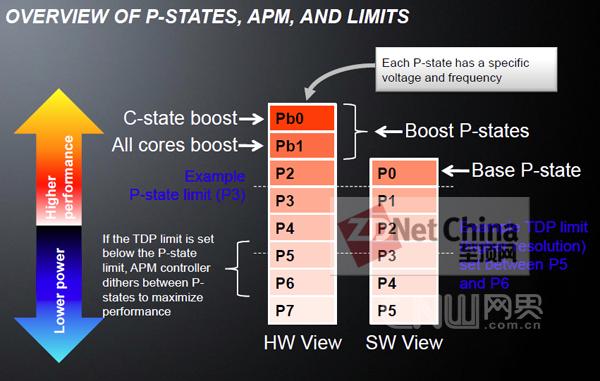
每个核心都有6个能耗/性能等级(P-States),可以根据TDP的设定而将最高性能限制在某一等级之下,而当与TurboCORE技术相配合时,我们能发现又多出两个等级,以提供最强的核心性能。在Opteron 6200平台上,用户可以在BIOS中通过AMD新推出的TDP Power Cap功能设定总功耗限制,而P-States也就会做出相应的限定
新增加的C6能耗控制状态,在这一状态,空闲的模块可以单独进入C6状态,此时模块停止供电与时钟信号,从而可最多节省95%的能耗。在Bulldozer处理器,每个模块的状态将保存在内存中

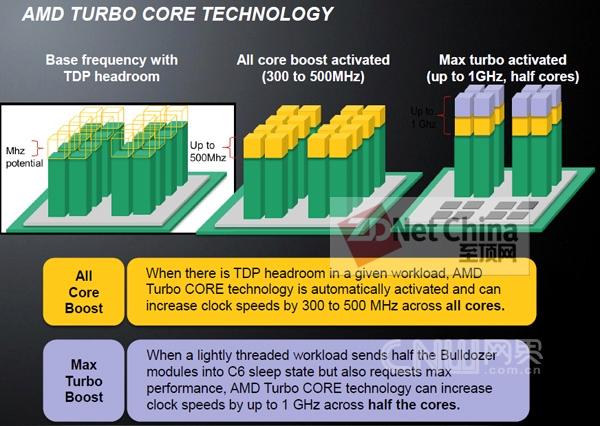
AMD TurboCORE技术实现了类似于英特尔“睿频”(TurboBoost)的功能
我们已经对英特尔的“睿频”技术有所了解,它可以在处理器的能耗不超出TDP功率限制的前提下,根据应用的性能需求,提升处理器核心的运行频率以最大限度挖掘核心的处理性能,而在Opteron 6200上也同样具备了这一能力,它就是AMD 的TurboCORE技术,它可分为两个模式。一种是All Core模式,所有的模块都可以提升300至500MHz的主频,另一种是Max Turbo,即如果一些轻负载线程让一半的模块可以将进入C6状态,但余下的模块又需要最大的处理性能,此时可以在All Core的基础上再增加500MHz(即最高可超频1GHz)。
Opteron 6200处理器价格信息与规格比较
我们在4月份曾做过Opteron 6100与至强7500和5600之间的对比。今天将延续我们以往的风格,我们在此会列出Opteron 6200的规格信息,以及与Opteron 4200的价格信息,并将开始与主要的竞争对手进行对比。在这里需要强调的是,从6100系列来,AMD就放弃了4路以上的服务器市场,并且主攻双插槽市场,这一点与英特尔的战略明显不同。所以,AMD将Opteron 6200定位于主流的双插槽及4路服务器市场,4200则主要是面向云计算集群应用以及轻负载的企业应用,只有双插槽平台可供选择。
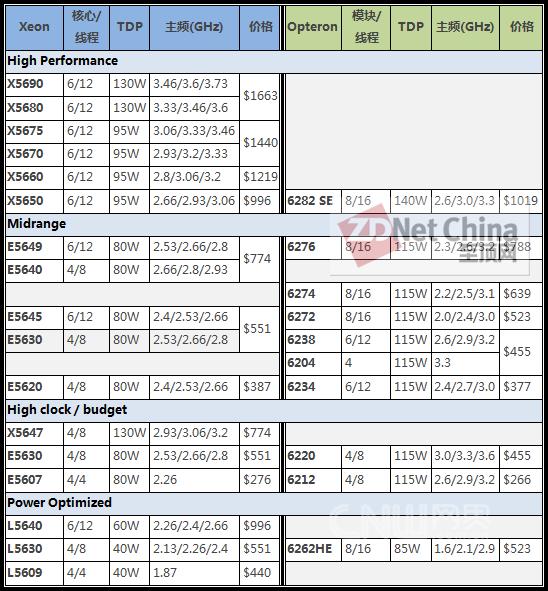
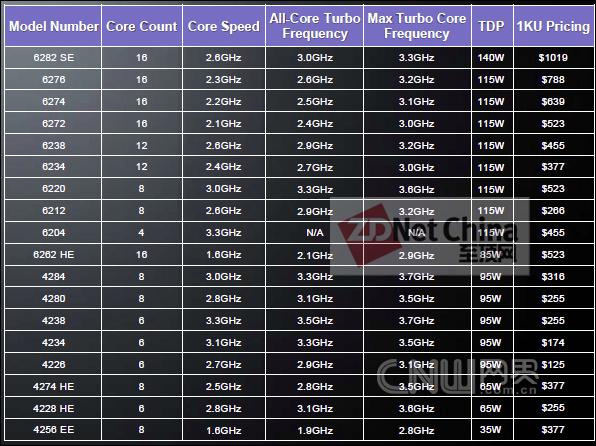
Opteron 6200与Opteron 4200的官方报价,4200最低价为125美元,6200最高为1019美元
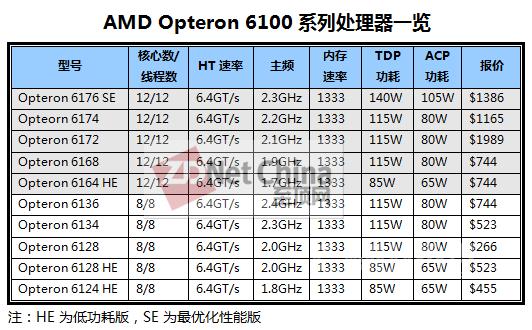
年初发布的6100系列处理器的价格表,可以看出6200居然更便宜
24.jpg
英特尔E7处理器的价格,4路型号最高价格4394美元,双插槽最高价格4227美元,相比之下Opteron 6200太廉价了……
25.jpg
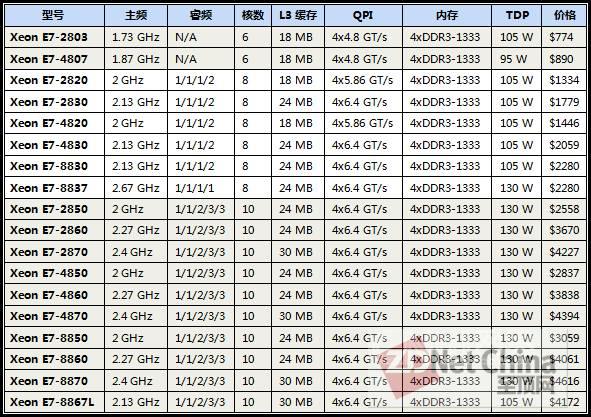
与6100一样,6200同样面对两个强大的对手,但4路平台从至强7500换成E7,而双插槽平台仍然是至强5600
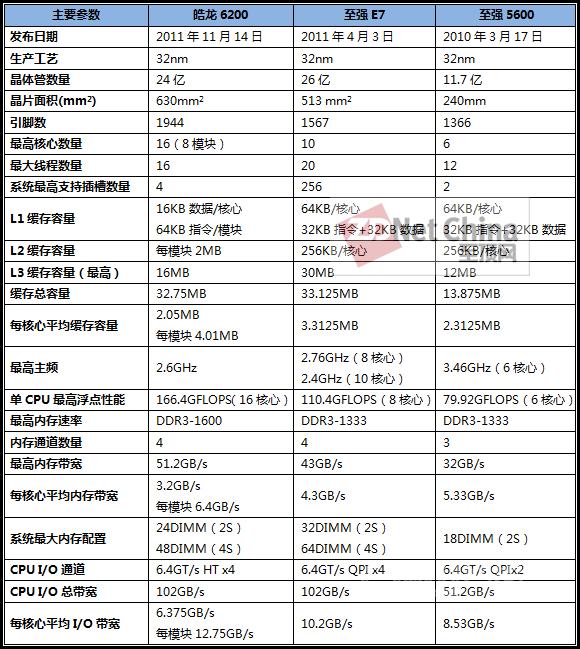
以价格段为区间,至强5600与Opteron 6200的型号对位表,这也将影响到我们下面的评测处理器的选择