






突破CFL桎梏:DGTD-FDTD高阶局部分步技术的算法创新与UltraLAB算力配置方案
时间:2026-03-24 13:53:31
来源:UltraLAB图形工作站方案网站
人气:52
作者:管理员
【导语】 当电磁系统涉及从微米级精细结构到百米级整机平台的多尺度建模,传统时域算法往往陷入"细网格拖累全局"的CFL困境。超大规模电磁计算团队最新提出的高阶局部分步(HOLTS)技术,通过泰勒展开边界与二阶有限差分边界的双重创新,在DGTD-FDTD混合框架下实现了45倍加速与20倍精度提升的双重突破。本文深度解析该技术的核心算法架构、计算瓶颈及面向多尺度电磁仿真的UltraLAB硬件配置方案。
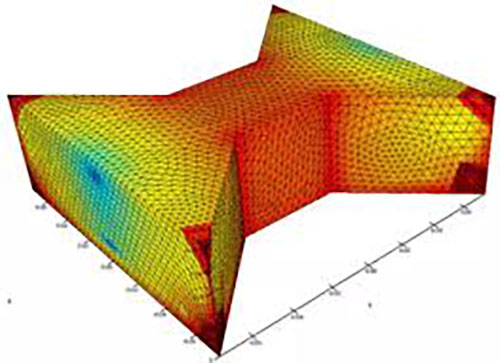
一、核心算法:双边界耦合的高阶局部分步架构
HOLTS技术的创新核心在于"时间异步但空间相容"的边界处理机制,解决了传统局部分步(LTS)在混合方法中引入近似误差的历史难题:
1.1 泰勒展开边界(DGTD内部LTS边界)
针对DGTD区域内部不同时间步长类别(LTS Classes)间的边界单元,采用高阶泰勒展开预测场值:
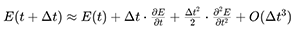
算法价值:消除传统LTS因时间不同步导致的近似误差,保持DGTD区域高阶精度(通常p≥2)的数值特性。
1.2 二阶有限差分边界(DGTD-FDTD杂交边界)
针对DGTD(非结构化网格)与FDTD(结构化网格)的混合边界,引入基于波动方程的二阶有限差分格式(SOFDE):
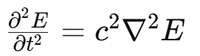
通过波动方程的时域离散化,确保两种方法在边界处的时空一致性,避免传统插值耦合导致的数值反射与能量不守恒。
1.3 混合时间步进策略
表格
| 区域类型 | 网格特征 | 时间步长 | 计算方法 |
|---|---|---|---|
| 精细结构区 | 非结构化、加密 | Δtfine | DGTD高阶基函数 |
| 粗糙背景区 | 结构化、均匀 | Δtcoarse=M⋅Δtfine | FDTD二阶差分 |
| 边界过渡区 | 混合网格 | 插值/预测 | HOLTS边界处理 |
关键突破:允许粗细区域时间步长比M 达到10-100量级,而不损失数值稳定性。
二、计算特点:多尺度问题的"时空不对称性"
DGTD-FDTD-HOLTS方法呈现鲜明的计算负载特征:
2.1 多尺度网格的内存非对称分布
-
DGTD区域(精细结构):非结构化四面体/六面体网格,需存储Jacobian矩阵、基函数系数、单元连通性,内存占用呈O(p3) 增长(p 为基函数阶数)
-
FDTD区域(背景空间):结构化笛卡尔网格,仅需存储场值数组,内存占用O(N)
-
边界区域:需同时维护两种网格的拓扑映射关系,内存开销最大
2.2 计算密度的区域差异化
-
DGTD区域:每时间步涉及质量矩阵求逆、通量计算、高阶积分,计算密度高但单元数量少
-
FDTD区域:简单的差分 stencil 计算,计算密度低但网格规模大(可能占总体积95%以上)
-
HOLTS边界:需存储多时间层历史场值用于泰勒展开,内存带宽敏感
2.3 时间步进的异步并行挑战
-
全局时间步:受限于CFL条件,
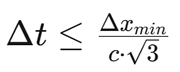
-
局部分步:不同区域以不同时间步长推进,需精确的"时间同步点"协调
-
负载均衡:精细区域步长小、计算密集;粗糙区域步长大、计算简单,传统MPI并行难以平衡
三、最大瓶颈:传统LTS的"精度-效率"死锁
3.1 CFL条件的全局限制(传统痛点)
在150m舰船的电磁散射仿真中,若存在毫米级精细结构(如缝隙、天线),传统全局时间步进要求: 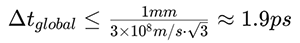
这意味着模拟100ns物理过程需要52,000个时间步,即便使用FDTD也需近3小时,纯DGTD更是长达36小时。
3.2 传统LTS的精度陷阱
传统局部分步技术在DGTD-FDTD混合中从未成功应用,根本原因在于:
-
时间插值误差:粗区域向细区域提供边界条件时,线性插值引入O(Δt2) 误差
-
能量非守恒:异步时间步进导致杂交边界处数值反射,长期积分后能量漂移
-
稳定性缺失:误差累积触发数值振荡,尤其在谐振结构中表现为 late-time instability
HOLTS的突破性:通过泰勒展开的预测精度与波动方程的差分相容性,将MSE(均方误差)降低20倍,同时仅增加5%计算开销。
3.3 内存墙与带宽瓶颈
-
历史场值存储:HOLTS边界需存储多时间层(通常3-5层)的场值用于高阶预测,内存占用较传统方法增加30-50%
-
非结构化网格随机访问:DGTD区域的稀疏矩阵-向量乘(SpMV)对内存带宽极度敏感,传统CPU缓存命中率低
-
混合精度需求:DGTD高阶计算需双精度(FP64)保证精度,FDTD区域可单精度(FP32)加速,硬件需支持混合精度
四、UltraLAB硬件配置方案推荐
针对DGTD-FDTD-HOLTS方法的多尺度、高内存、异步并行特征,推荐以下UltraLAB图形工作站/服务器配置:
配置一:多尺度电磁仿真工作站(课题组研发级)
定位:适用于舰船、平台级目标的中等规模电磁散射仿真,支持DGTD-FDTD混合网格建模与HOLTS算法验证
| 组件 | 推荐规格 | 技术理由 |
|---|---|---|
| CPU | Intel Xeon W9-3595X (60核/120线程, 4.8GHz) | 高主频加速DGTD区域的小规模密集计算;多核并行处理FDTD大规模网格更新 |
| 内存 | 512GB DDR5-4800 ECC (8×64GB) | 150m舰船模型网格规模约5000万单元,混合方法需存储电场、磁场、历史场值、Jacobian矩阵,内存峰值约300-400GB |
| 存储 |
系统:2TB NVMe Gen4 SSD 数据:8TB NVMe SSD (企业级U.2) 缓存:Intel Optane P5800X 800GB (可选) |
NVMe高速IO加速中间结果 checkpoint 写入;Optane提供极低延迟随机读写,缓解非结构化网格访存瓶颈 |
| 加速卡 | 1× NVIDIA RTX 6000 Ada (48GB显存) | CUDA加速FDTD区域的大规模并行更新;48GB显存可卸载部分DGTD区域的稀疏矩阵运算 |
| 网络 | Dual 10GbE | 集群扩展预备,支持多机MPI并行 |
UltraLAB型号推荐:UltraLAB GT430P(Xeon W工作站)
性能预估:在该配置上,150m舰船模型HOLTS仿真可在1小时内完成,较纯DGTD(36小时)提升36倍。
配置二:超大规模电磁计算服务器(团队/平台级)
定位:支持电大尺度目标(飞机、舰船编队)的全波仿真,具备百亿级网格处理能力
| 组件 | 推荐规格 | 技术理由 |
|---|---|---|
| CPU | 2× AMD EPYC 9654 (96核/192线程, 3.7GHz) | 更多核心数支撑大规模MPI并行;更高内存带宽(460GB/s)缓解DGTD SpMV瓶颈 |
| 内存 | 1TB DDR5-4800 ECC (16×64GB) | 支持10亿+网格单元的全波仿真;ECC纠错保障长时间计算的数值稳定性 |
| 存储 |
系统:2TB NVMe RAID1 数据:16TB NVMe SSD (4×4TB RAID 0) 归档:4× 20TB HDD RAID6 |
RAID 0提供超高速并行写入(适合时域仿真的频繁checkpoint);RAID6保障原始数据安全 |
| 加速方案 | 2× NVIDIA A100 80GB (NVLink互联) | NVLink提供600GB/s P2P带宽,支持DGTD-FDTD混合算法的异构计算;80GB显存可处理大规模非结构化网格的GPU加速 |
| 互联 | Mellanox ConnectX-6 (100GbE/IB HDR) | 支持跨节点MPI并行,降低HOLTS边界数据交换延迟 |
UltraLAB型号推荐:UltraLAB EA660(双路EPYC服务器级工作站)或 UltraLAB GA660M(4路GPU服务器)
配置三:算法开发与验证工作站(个人/博士生级)
定位:算法原型开发、中小规模验证、参数调优
| 组件 | 推荐规格 |
|---|---|
| CPU | Intel Core i9-14900K (24核, 6.0GHz) |
| 内存 | 128GB DDR5-6000 |
| 存储 | 2TB NVMe + 4TB NVMe |
| 显卡 | RTX 4080 (16GB) |
| 特性 | 静音设计,适合办公室环境;高频CPU加速小规模调试 |
UltraLAB型号推荐:UltraLAB A330(单路旗舰工作站)
五、软件生态与优化建议
5.1 核心软件栈
-
DGTD求解器:自研代码(基于MFEM/deal.II框架)或商业软件(如JMAG、CST的TLM模块)
-
FDTD求解器:自研CUDA代码或开源Meep、B-CALM
-
网格生成:Gmsh(非结构化)、Cubit(混合网格)、HyperMesh(工程级)
-
后处理:ParaView(场可视化)、Python/Matlab(S参数/RCS提取)
5.2 性能优化策略
-
内存布局优化:DGTD区域采用SoA(Structure of Arrays)存储,提升缓存命中率
-
混合精度计算:FDTD区域使用FP32,DGTD区域保持FP64,平衡精度与速度
-
异步并行:OpenMP线程绑定(thread affinity),DGTD与FDTD区域分配到不同NUMA节点,避免资源争抢
六、结语:算法创新与算力进化的协同
HOLTS技术的成功应用证明,算法层面的高阶边界处理与硬件层面的异构并行是突破多尺度电磁仿真瓶颈的双重引擎。从150m舰船的45倍加速到20倍精度提升,这一成果不仅代表了计算电磁学的前沿进展,更预示着自主工业软件(CAE/EDA)在超大规模电磁计算领域的突破。
UltraLAB针对时域电磁仿真中高内存带宽、大容量存储、异构计算的需求,提供从个人工作站到集群节点的全栈硬件解决方案,助力科研团队攻克"卡脖子"核心算法,加速国产电磁工业软件的自主研发。
【关于UltraLAB】
UltraLAB是西安坤隆计算机科技有限公司旗下定制图形工作站品牌,专注于计算电磁学(CEM)、计算流体力学(CFD)、多物理场耦合等高性能计算场景,提供从算法验证到工程应用的全链条算力支撑。
UltraLAB是西安坤隆计算机科技有限公司旗下定制图形工作站品牌,专注于计算电磁学(CEM)、计算流体力学(CFD)、多物理场耦合等高性能计算场景,提供从算法验证到工程应用的全链条算力支撑。
本文技术内容基于超大规模电磁计算团队发表于Electronics Letters的研究成果,硬件配置方案由UltraLAB计算电磁学技术团队针对DGTD-FDTD-HOLTS算法特征优化设计。
UltraLAB图形工作站供货商:
咨询微信号:xasun001
西安坤隆计算机科技有限公司
国内知名高端定制图形工作站厂家
业务电话:400-705-6800

上一篇:没有了


