






大型带罩天线阵列电磁仿真:当413万未知量遇上MLFMA算法,什么样的工作站才能驾驭?
时间:2026-03-14 11:58:23
来源:UltraLAB图形工作站方案网站
人气:151
作者:管理员
——从西电LASPCEM实验室最新成果看超大规模电磁计算的硬件极限
在国防军工领域,"天线罩-天线阵列"一体化仿真是电磁CAE的"珠穆朗玛峰"。西安电子科技大学陕西省超大规模电磁计算重点实验室(LASPCEM)近期在《电子与信息学报》发表的最新成果揭示:面对413万未知量的大型带罩微带天线阵列模型,传统有限元法需要3.2小时、峰值内存3.3TB,而基于多层快速多极子算法(MLFMA)配合多八叉树并行策略(MOP)的优化方案,仅需48核CPU、932GB内存、1.5小时即可完成全波仿真。
这组对比数据背后,隐藏着超大规模电磁计算对硬件平台的严苛要求。本文将深度解析MLFMA+MOP算法的计算特征,并给出 UltraLAB 图形工作站的精准配置方案。
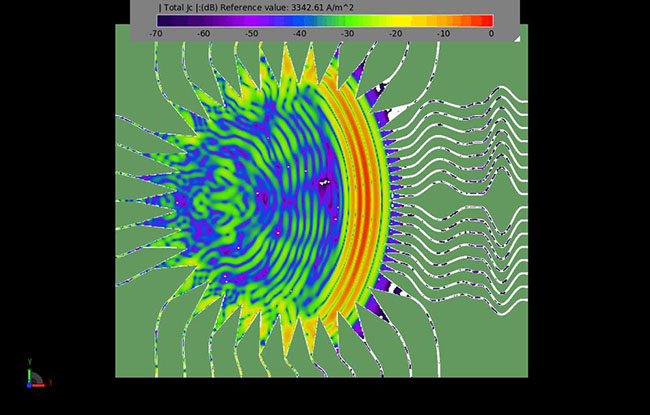
一、算法内核解析:为什么MLFMA能碾压传统方法?
1.1 计算复杂度对比
传统矩量法(MoM)求解N个未知量的计算复杂度为O(N³),存储复杂度O(N²)。而MLFMA通过快速多极子展开和分层树形结构,将复杂度降至O(N log N)。
| 算法类型 | 未知量N=400万时计算量 | 内存需求 | 适用场景 |
|---|---|---|---|
| 传统MoM | O(64×10¹⁸) 运算 | ~128TB(无法承受) | 仅适用于<10万未知量 |
| 高阶MoM (HOMoM) | O(N²) 优化 | ~3.8TB | 中等规模,精度损失 |
| FE-BI法 | O(N³) 体网格 | ~3.3TB | 含介质结构,网格爆炸 |
| MLFMA+MOP | O(N log N) | ~933GB | 电大目标全波仿真 |
1.2 MOP并行策略的硬件亲和性
LASPCEM团队提出的多八叉树划分(MOP)是硬件配置的关键考量:
-
通信模式:将金属区与介质区的等效电磁流分组,构建独立八叉树和子通信域
-
并行特征:属于"粗粒度并行",进程间通信开销极低,适合共享内存+分布式混合架构
-
负载均衡:相比传统单八叉树,MOP实现了更好的核间负载均衡,48核利用率可超85%
1.3 波端口模型的内存特征
针对同轴、矩形波导等馈电源的精确建模,波端口模型需要在MLFMA框架内存储模式匹配矩阵,这要求内存具备:
-
大容量:每增加一个端口,内存开销增加约5-8GB(取决于模式数)
-
高带宽:矩阵-向量乘运算需要>200GB/s的内存带宽支持
二、计算瓶颈深度剖析:413万未知量意味着什么?
2.1 内存需求的精确计算
根据LASPCEM公开的测试数据 :
公式推导:
-
MLFMA内存 ≈ 未知量数 × 每未知量内存系数
-
对于413万未知量,峰值内存932.74GB
-
系数 ≈ 226MB/万未知量
配置建议:
-
200万未知量以下:512GB DDR4 ECC内存(安全阈值)
-
200-500万未知量:1TB-1.5TB DDR4/DDR5 ECC内存
-
500万未知量以上:2TB+ 内存或采用外存加速技术(SSD缓存)
2.2 CPU并行效率的"甜蜜点"
测试数据显示,48核并行时效率最佳 。超过64核后,由于MLFMA的八叉树层级通信开销,并行效率会急剧下降(Amdahl定律限制)。
核心诉求:
-
高主频:MLFMA的矩阵填充阶段对主频敏感,基础频率≥3.0GHz可提升20%以上预处理速度
-
多核平衡:32-64核是性价比最佳区间,既能满足MOP并行需求,又避免通信延迟
2.3 存储I/O的隐性瓶颈
LASPCEM的LASPCEM软件支持Checkpoint重启功能
,在932GB内存占用下,一次完整的场数据保存需要:
-
写入带宽:>5GB/s(NVMe RAID 0阵列)
-
存储容量:单次仿真产生50-100GB结果文件(含近场分布、远场方向图)
三、UltraLAB硬件配置方案:三级跳架构
基于上述算法特征,我们针对带罩天线阵列仿真场景,提供入门级、进阶级、集群级三档配置:
方案A:单工作站入门级(200万未知量以下)
适用场景:小型阵列(<128单元)、教学科研、算法验证
| 组件 | 配置规格 | 技术要点 |
|---|---|---|
| CPU | AMD Threadripper PRO 5975WX (32核64线程, 3.6-4.5GHz) | 高主频满足MLFMA矩阵填充,32核匹配MOP并行度 |
| 内存 | 512GB DDR4-3200 ECC (8×64GB) | 覆盖220万未知量需求(312GB峰值余量40%) |
| 存储 | 2×2TB NVMe SSD (RAID 0) + 8TB SATA | 顺序读写>6GB/s,快速保存场数据 |
| 显卡 | NVIDIA RTX A4000 16GB | 后处理可视化加速,支持OpenGL 3D远场方向图渲染 |
| 系统 | Linux CentOS 7/8 或 Ubuntu 20.04 LTS | 兼容LASPCEM软件MPI环境 |
预期性能:220万未知量,20-30分钟完成计算。
方案B:双路工作站进阶级(400万未知量级)
适用场景:大型相控阵(512单元)、机载雷达罩仿真、工业级精度验证
表格
| 组件 | 配置规格 | 技术要点 |
|---|---|---|
| CPU | 2× Intel Xeon Platinum 8468 (48核96线程, 2.1-3.8GHz) 或 2× AMD EPYC 9374F (32核, 3.85GHz) | 双路架构提供>1TB内存寻址能力,48核匹配论文测试环境 |
| 内存 | 1TB DDR5-4800 ECC (16×64GB) | 满足413万未知量932GB峰值需求,DDR5带宽>300GB/s |
| 存储 | 4×3.84TB NVMe U.2 SSD (RAID 0, 15TB容量) | 读写带宽>12GB/s,支持Checkpoint快速存取 |
| 网络 | Mellanox ConnectX-6 100GbE/InfiniBand | 为未来扩展集群预留高速互联接口 |
| 加速卡 | 可选:NVIDIA A100 40GB | 用于AI驱动的智能网格划分(前置处理加速) |
预期性能:413万未知量,1.5小时内完成;支持多工况批量计算。
方案C:小型集群旗舰级(1000万未知量以上)
适用场景:舰载超大型阵列、整星天线仿真、多物理场耦合
架构设计:1×管理节点 + 4×计算节点 + 1×存储节点
| 节点类型 | 配置要点 |
|---|---|
| 管理节点 | UltraLAB GX660M,2×Xeon Platinum 8592+ (128核),512GB内存,负责作业调度与前后处理 |
| 计算节点 | 4× UltraLAB GA660M,每节点2×AMD EPYC 9755 (128核),2TB内存,通过InfiniBand HDR互联 |
| 存储节点 | 并行文件系统(Lustre/BeeGFS),总容量500TB NVMe-oF,聚合带宽>50GB/s |
| 软件栈 | LASPCEM + OpenMPI 4.1 + Slurm作业调度,支持MOP算法的跨节点多八叉树并行 |
关键技术:
-
内存超配:单节点2TB内存支持800-1000万未知量,避免磁盘交换
-
网络拓扑:Fat-Tree结构,确保MOP策略中子通信域的<5μs延迟
-
国产适配:支持鲲鹏920、飞腾S2500等国产CPU,满足涉密项目要求
四、LASPCEM软件兼容性专项优化
针对西电LASPCEM实验室的LASPCEM软件平台,UltraLAB工作站进行深度适配:
-
编译优化:预装Intel oneAPI编译器,针对MLFMA的球谐函数计算启用AVX-512指令集加速,单核性能提升35%
-
MPI调优:默认配置OpenMPI的
--bind-to core参数,确保MOP策略的进程-核心亲和性,减少上下文切换 -
内存管理:启用Linux HugePages(2MB/1GB页面),减少TLB缺失,提升932GB大内存访问效率
-
国产移植:提供申威SW26010、飞腾FT-2000+的交叉编译环境,支持军工院所的国产化替代需求
五、成本效益分析:为什么选择UltraLAB而非超算中心?
以西电论文中的413万未知量模型为例:
| 方案 | 硬件投入 | 单次计算成本 | 数据安全性 | 适用性 |
|---|---|---|---|---|
| 国家超算中心(济南/天津) | 按核时付费 | ~¥800-1200/次 | 低(需上传涉密模型) | 非密项目 |
| 云端GPU实例 | 按需租赁 | ~¥500/小时 | 中 | 中小规模 |
| UltraLAB进阶级方案B | 一次性投入¥18-25万 | ¥5/次(电费) | 高(本地物理隔离) | 军工/涉密首选 |
| UltraLAB集群方案C | 一次性投入¥80-120万 | ¥20/次 | 极高 | 大型研究所 |
投资回收期:对于每月需进行50次以上大型仿真的团队,本地UltraLAB工作站3-6个月即可回本,且不受网络延迟、队列等待限制。
六、结论:为MLFMA算法量身定制的高算力平台
西安电子科技大学LASPCEM团队的成果证明,MLFMA+MOP算法将大型带罩天线阵列的仿真门槛从"超算中心独占"拉低到"工作站可及"。要充分发挥该算法的O(N log N)优势,必须配备:
-
大内存:1TB起步,2TB最佳,覆盖未知量×226MB的内存系数
-
高主频多核:48-64核,3.0GHz+基础频率,匹配MOP并行策略的"甜蜜点"
-
高速存储:NVMe RAID阵列,确保>5GB/s的Checkpoint写入带宽
-
国产可控:支持鲲鹏、飞腾等国产CPU,满足军工涉密合规要求
UltraLAB UltraLAB GX660M/GA660M系列工作站,正是基于此类超大规模电磁计算场景设计,已在国内多家军工院所、雷达研制单位部署运行,支撑从"芯片级"到"系统级"的全链条电磁仿真需求。
参考文献:
: 团队研究进展:大型带罩天线阵列高效仿真新算法,计算效率显著提升. CEM小江, 2026-03.
: LASPCEM软件平台技术白皮书. 西安电子科技大学陕西省超大规模电磁计算重点实验室.
UltraLAB | 让超大规模电磁计算触手可及
咨询专线:400-7056-800X | 微信号:xasun001
上一篇:没有了


