






GPU让桌面型超级计算机不再是梦想
GPU(图形处理器)正在高性能计算领域掀起一股新风:GPGPU计算。
GPGPU计算是一种异构模式,由CPU负责执行顺序型的代码,如操作系统、数据库等应用,而由GPU来负责密集的并行计算。打个比方说,假设让10个人把各自塑料瓶子的水倒入一个大桶中,CPU的做法是让这10个人按着顺序一个一个往里面倒,而GPU的做法则是在设定好一定规则的前提下让10个人同时或分组往里面倒。因此,在高性能计算领域,可以把CPU服务器和GPU服务器结合起来,构成一个混合型的集群,各司其职,会大大提高集群系统的总体计算效能。
7月25日,NVIDIA在北京举办了一场小规模的媒体专访,其Tesla GPU 计算事业部高级产品经理Sumit Gupta首次向中国媒体系统、全面地介绍了NVIDIA的Tesla GPU计算机和专门针对GPU的C语言开发工具CUDA。
A1.jpg

个人桌面型超级计算机不再是梦想
传统上,人们一提及超级计算机,往往想到的是机房里整柜整柜的宏然大物。但你是否知道,如果用GPU来构建,你甚至可以把原来超级计算机要做的事浓缩到一个普通的台式工作站或机架服务器中去呢?因为目前的X86处理器只集成了4个内核,而GPU已经拥有数以百计的内核,在高密度并行计算方面拥有得天独厚的优势。
据Sumit Gupta介绍,相对于传统的服务器集群,GPU超级计算机在性价比、占地空间、功耗等方面的优势非常明显。他举了一个“台式GPU超级计算机击败服务器集群”的例子:某大学原来用的超级计算机有512颗处理器核,构建成本是530万美元,而且这套超级计算机是由全校共同来使用;而如果换成一台拥有8个GPU的台式机(9800GX2),性能相当,而成本只有7000美元,而且可以为每个研究人员在桌边配备一台。
“每个人都可以拥有自己的桌面超级计算机,而不是大家来共享一台大型的超级计算机。这不是简单的芯片的性能提升,而是带来了一种全新的、具有革命性的计算模式。” Sumit Gupta在访谈中多次强调了这一点。
在许多领域,GPU计算甚至超过了传统的计算机,让许多原来无法解决的问题现在可以通过GPU计算机来轻松实现。比如,针对新型流行性疾病如非典禽流感等,人们总是希望新药物研制的时间越短越好;在天气预报方面,人们希望预报的精度和准确度越高越好;在金融股票价格分析方面,人们在决定买卖股票时总是希望越快越好。GPU计算的出现,使得超级计算机在挑战这些领域极限方面又进了一步。比如,美国国家癌症研究所通过GPU计算将模拟速度提升了12倍,等待结果的时间从原来的2个小时缩短到了10分钟;美国国家大气研究中心的气象研究和预报模型(WRF)尽管仅仅将1%通过CUDA来实现,但其总体速度却提升了20%,节省了一个星期的分析时间;在评估整个美国期权市场时,Hanweck原来计划用价值26.2万美元的600 CPU集群来处理,而实际采用三台nvidia Telsa S870后,机架空间节省了9倍,硬件成本节省了6倍。这就是GPU加速带来的魅力!
A2.jpg

在国内,也有一些机构正在从GPU计算中获得好处。清华大学微电子学研究所的邓仰东副教授已经成功实现了“基于CUDA的电子设计自动化(EDA)并行计算”。
他告诉记者,由于现在大规模集成电路芯片中的晶体管数量越来越多,动辄数以亿计,结构越来越复杂,加上昂贵的制造成本,在设计集成电路时必须用到EDA软件来进行模拟计算。但单核CPU的性能已经饱和,虽然通过多核CPU可以重复使用以前的代码,但也面临一些问题,如为保持数据一致性的数据锁会导致性能下降,在计算结果上会排除最优解等等。“多核CPU只取得了有限的成功,到了10核以上,加速比就无法再提高,而在GPU平台上使用CUDA,可以让EDA从粗粒度、任务级的并行转向细粒度、数据级的并行。” #p#page_title#e#
据介绍,在使用CUDA后,项目组在静态时序分析上实现了80倍的加速比,全芯片STA从CPU所需要的1小时缩短了用GPU的1分钟,意味着可以实时得到结果,尝试更多设计;在故障仿真上实现了200倍的加速比,让原来CPU一周的工作量缩短到了GPU的一个小时,原来需要用一套集群来模拟,现在只需要一块GPU卡;在电路布局方面也取得了3倍的加速比,从而允许每天可以多做1-2次优化。邓仰东表示,后续还会用CUDA来实现EDA更多流程的并行化。
Sumit Gupta还介绍了GPU计算在消费电子领域的应用,如为了把一段影片转换成iPod可以播放的格式,原来在普通电脑上可能需要15分钟,而用GPU只需要1分半钟。另外,在照片编辑、人脸识别、电子游戏等方面GPU计算也大有可为。很多原来需要用到集群超级计算机来完成的任务,现在用一台GPU电脑就可以实现了。
T10:NVIDIA第二代CUDA处理器
CUDA虽然发布只有一年半的时间,但现在已经有很多领域在使用。Nvidia所要做的是要让人们可以在网上找到免费的软件,而且让自身的GPU产品支持CUDA。据Sumit Gupta介绍,NVIDIA T8系列以上Telsa产品都将支持CUDA。截止到目前,CUDA GPU的市场保有量已经达到了8000万颗。
而在今年的8月份,NVIDIA还将向市场提供其第二代CUDA处理器——T10系列。T10 GPU可谓是当前世界上最大的芯片,拥有14亿个晶体管,共有240个核心,一块这样的GPU卡的浮点运算性能可达到1万亿次每秒(Tflops),而现在一颗四核CPU只有每秒700亿次浮点计算。
A3.jpg
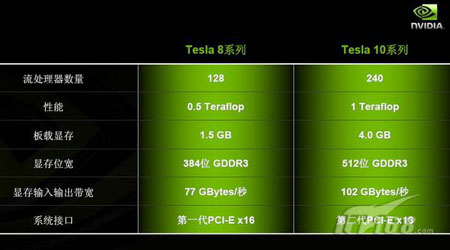
跟T8系列相比,T10在性能和显存容量上都增加了一倍,还增加了双精度的支持,从而能更好地加速汽车飞机设计、CFD计算流体动力学以及金融分析等需要高准确度的应用。由于高性能计算应用的数据量往往很大,需要用到大容量内存,所以T10的板载显存容量也从原来的1.5GB提升到了4GB。NVIDIA工程师在逆时偏移测试时发现,在同样配置1.5GB内存时,T10仅比G80提升了1.9倍,而如果把内存加大到4GB,性能会提高到3.5倍。
Nvidia还推出了两款基于T10的GPU新产品:一款是Telsa S1070 1U机架服务器,共有4个GPU卡,共960个内核,性能达到4万亿次每秒,功耗只有700瓦,而如果要达到相同计算性能,需要一个小服务器集群才能实现,而功耗可能达到几万瓦;另一款产品是Telsa C1060,可以用到普通的PC和工作站中,性能是957Gflops,功耗只有160瓦。
A4.jpg

A5.jpg

假设要构建一个具有100万亿次规模的数据中心,如果完全采用基于CPU 的1U服务器,需要用到1429台四核服务器,成本高达310万美元,功耗571KW;而如果采用CPU+GPU的异构模式,则仅需要25台CPU服务器和25台Telsa系统,仅需31万美元,功耗只有27KW。
据了解,在GPGPU集群中,CPU服务器负责执行顺序型任务,如操作系统和数据库,CPU服务器与CPU服务器之间通过Infiband进行连接通信,GPU服务器则作为“一种协处理器的拓展”,通过PCI-E2.0连到CPU服务器上,承担并行计算任务。由于GPU服务器上没有CPU,所以操作系统的启用需要用到CPU服务器。用户可以根据顺序任务和并行任务的比率,来配备CPU核与GPU核的不同数量。
象学C语言一样学习CUDA
对于高性能并行计算而言,硬件和软件是不可分割的两大支撑。NVIDIA对GPU架构进行了根本性的改变,使其可以用C语言来编程。为了理解CUDA的作用,不妨让我们回到本文开头的那个比方,10个人轮流地向桶中倒水的顺序比较容易控制,而当10个人并行地向桶中倒水时,如何保证效率呢?Sumit Gupta调侃道,“CUDA在GPU多核并行计算中起到的作用就好比是军队里的将军一样,通过它来保证并行高效有序地实现。” 跟CELL、FGPA以及其他GPU相比,CUDA环境支持已经成为NVIDIA GPU计算的一大优势,用户借助CUDA可以更加方便地使用GPU计算。 #p#page_title#e#
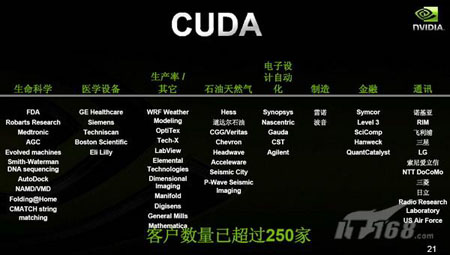
Sumit Gupta告诉记者,过去并行编程语言只有一两所大学或一两个研究机构在使用,而现在CUDA是全球第一个广泛使用的并行编程环境。CUDA的客户数量已经达到了250家,涉及生命科学、医学设备、工业生产、石油天然气、电子设计自动化、制造、金融、通讯等多个领域。CUDA有英文、中文、日文、韩文和西班牙语等多个版本,支持Linux、Windows、Mac OS等多种操作系统,全球有50多所大学开设了CUDA并行编程课程。清华大学、中科院等也将陆续开通CUDA的教育培训。“也许以后学生要象学C语言一样学习CUDA。”A6.jpg
据了解,开发人员只要用CUDA开发一次程序,就既可以在CPU上运行,也可以在GPU平台中使用。这样,当用户没有用到GPU的时候,就可以在普通电脑上使用。可见,尤其对于新创的小型软件厂商来说,CUDA是一个挑战大ISV的不错机会。
虽然CUDA 1.0发布只有一年的时间,但截止到2008年6月份,CUDA编译器下载量已经达到了10万,CUDA GPU市场保有量也达到了8000万颗。CUDA2.0版本将开始支持多个处理器和多核心。
Sumit Gupta表示,下一步,CUDA会支持FORTRAN和C++,未来还将让两个GPU直接通信而不需要经过CPU,可以进行多核多线程调试,推出GPU群集管理软件等等。
小结:GPU Vs. CPU
Sumit Gupta认为,计算机的发展存在两条路线,一条是多核X86 CPU针对数据库、操作系统等顺序执行的处理架构,另一条是多核GPU的高性能并行计算架构。
A7.jpg
由于受到空间、电力、冷却等因素的限制,高性能计算系统从过去的高主频单核X86处理器转向了多核,但多核系统目前也面临着“内核数超过16个以后性能无法随内核数线性扩展”以及并行软件限制等问题,在这一背景下,GPGPU等加速技术的出现,为高性能计算带来了新的希望。于是,我们看到,IBM用12960颗Cell核心和6948颗双核AMD Opteron处理器构建起了全球第一台每秒运算一千万亿次的超级计算机走鹃,AMD在整合ATI之后启动了把CPU和GPU内核集成到一个芯片中去的Fusion计划,英特尔计划明年发布Larrabee处理器进入高端图形市场,NVIDIA Telsa和CUDA更是让人们清晰地看到了GPU进军高性能计算领域的新气象。
Sumit Gupta认为,将CPU和GPU集成在一起的做法对中低端市场会比较有意义,而对于高端市场,大型GPU加上少数CPU的做法会更具优势。而后者,正是NVIDIA目前和未来要拓展的一块全新的业务。


