






GPGPU将取代CPU?抢CPU “饭碗”
如果你希望流畅地播放高清视频,一定会选择一款支持NVIDIA PureVideo或AMD Avivo的显卡(这里指以前的ATI,由于ATI已经被AMD收购,本文中统称为AMD)。视频解码原本是CPU的工作,可即便是双核处理器,在播放1080p高清电影时仍然比较吃力。利用显卡的PureVideo/Avivo视频解码加速功能,可以大大降低CPU的占用率,让高清视频能够流畅地播放。从广义来看,用显卡来加速视频解码,这就是GPGPU的一种初级形态。
GPGPU,也有人形象地称为GP2U(GP的两次方U)。这两个GP代表了不同的含义,后一个GP表示图形处理(Graphic Process),和U加在一起正是我们熟知的GPU(图形处理器);前一个GP则表示通用目的(General Purpose),所以GPGPU一般也被称为通用图形处理器或通用GPU。
在3D领域,GPU的用途很简单,就是为了更好地渲染3D场景,减轻CPU在图形运算方面的负担。而时下刚刚出台的GPGPU,则是将应用范围扩展到了图形之外,无论是科研教育、财务计算,还是在工业领域,GPGPU都得到了广泛的使用,关于它的科研成果和新应用模式也层出不穷。
GPGPU比CPU强在哪里?
细心的读者可能会问了,发展GPGPU有必要吗?难道还有什么工作是GPU可以做,而CPU不能完成的?没错,CPU是一种通用处理器,它无所不能,但是在某些特定场合,它的能力又是相对有限的。
1.CPU的浮点运算能力严重不足
和GPU相比,CPU最大的软肋就是浮点运算能力不足。现在主流的CPU产品,无论是Intel的还是AMD的,其浮点运算能力大多在10Gflops以下(flops表示每秒钟能够完成的浮点运算次数,Gflops代表每秒10亿次浮点运算)。而GeForce 6系列的浮点运算能力就已经达到了40Gflops左右,GeForce 7950 GX2的浮点运算能力更是达到了384Gflops。可见,CPU和GPU的浮点运算能力差距已不止一两个数量级。
2.GPU的输入/输出带宽远超CPU
如果输入/输出带宽有限,纵然内部性能再强,也是无法被系统利用起来的。对于GPU而言,这并不是一个大问题,作为提高场景真实度的一个重要方法,纹理映射功能很早就被加入到了GPU中,以解决GPU和显存之间的输入/输出带宽问题。GPU和显存之间的带宽是CPU和内存的10倍以上,GPU是“吃得下”,也“吐得出”,让巨大的浮点运算能力有了用武之地。

AMD的“流处理器”(Stream Processor)
3.GPU更适合重复的计算
GPU因为是专门为图形运算而设计的,考虑到了图形运算的特殊性。拿像素着色器(Pixel Shader)来说,当前批次所有的待处理像素,都会执行相同的像素着色程序,也就是说,相同或类似的运算会在海量的数据上重复运行。这恰恰符合SIMD(单指令多数据)的概念,让GPU非常适合处理SIMD运算,科学计算、数据库分析等高性能计算正是SIMD类型。因此不少在CPU上伤透脑筋的科研人员不得不将目标转向GPU,试图利用GPU的这种优化设计来进行图形之外的通用计算。
4.GPU拥有优秀的编程语言
当GPU的程序员在编写程序时,会发现高级着色语言也会给他们不少帮助。以前编写着色程序需要使用汇编语言,难度大、效率低,如今具有类C/C++的高级语言能够极大地提高程序员的编程效率。微软的HLSL、OpenGL的GLSL、斯坦福大学的RTSL,以及NVIDIA的Cg等高级着色语言都能够隐藏掉底层硬件的技术细节,提高GPU的开发效率。在这一点上,尽管CPU的编程语言走在前列,但GPU也已经逐渐赶了上来,开发和利用GPU比以前容易得多了。


DirectX 10时代的到来,将让GPU更加适合通用计算
看到这里,你应该会疑惑,为什么对比的是GPU和CPU,GPGPU和GPU有什么区别?这是因为,GPGPU就是以GP为基础开发的,GPU的优势也正是GPGPU的优势。从狭义的GPGPU来讲,它在GPU的基础上进行了优化设计,使之更适合高性能计算,并能使用更高级别的编程语言,在性能和通用性上更加强大。 #p#page_title#e#
DirectX 10让GPGPU迎来黄金时代
虽然GPGPU早在DirectX 9时代就已经初现雏形,但只有在DirectX 10时代,新的GPU才能够真正促进GPGPU的成熟和高速发展。在浮点运算能力上,GeForce 8800 GTX的浮点运算能力达到了520 Gflops,是上一代顶级GPU的3倍以上!在输入/输出带宽方面,上一代GPU只能最多访问4个顶点纹理和16个像素纹理,而DirectX 10时代的GPU可以最多访问128个纹理,纹理尺寸达到8192×8192,对于着色程序来说,这就等于“无限”!让GPU和显存可以实现充分地互访。此外,GPU的通用计算主要是使用其像素着色器,上一代GPU的顶点着色器则毫无用武之地,而从NVIDIA的G80和AMD的R600开始,DirectX 10的GPU都会采用统一着色器,所有的着色器都能用于通用计算,不会造成资源的浪费
B4.jpg

AMD的两种物理解决方案
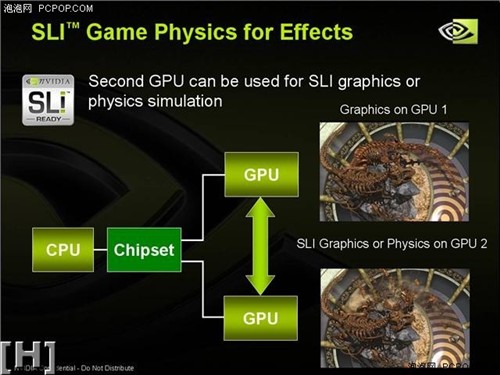
NVIDIA的SLI物理解决方案
除了硬件的巨大进步,Shader Model和着色语言的成熟也将有力地助推GPGPU的发展。由于早期的Shader Model 1.0和Shader Model 2.0不支持动态流控制,只能提供有限的灵活性,阻碍了GPU的通用化。在DirectX 9.0c时期,动态流控制和着色程序几乎无限的资源访问能力,减少了编程时的限制。而在DirectX 10时代,Shader Model 4.0在动态流控制和资源访问上让程序员更加得心应手,几乎不用再担心编写程序时有任何限制,这也将让GPGPU在新时代的应用有了更多的可能性。关于DirectX 10和Shader Model 4.0的详细介绍,请参看本刊2006年8月上的《走进DirectX 10》和8月下的《Shader Model 4.0绝密解封》。
GPGPU就在我们的身边
依靠上述优势,GPGPU在图形运算之外,能完成一些原本由CPU来处理的工作,以实现更高的处理速度和效率。
B6.jpg

GPGPU模拟风在城市环境下(纽约时代广场)的流动情况
B7.jpg

GPGPU模拟烟雾的扩散效果。在纽约大学30颗GPGPU的集群上,它也只能在480×480分辨率下达到每秒80帧的绘制速度,勉强达到实时性的要求,由此可见流体物理所需要的计算能力有多高。
GPGPU看上去很遥远,但它实际上就在我们的身边。视频的编解码原本是CPU在负责处理,但由于高清视频的盛行,庞大的数据运算量让CPU不堪重负。而在播放高清视频时,GPU本来是不参与处理的,强大的性能基本处于闲置状态。因此NVIDIA和AMD分别开发了PureVideo和Avivo技术,利用GeForce 6/7系列和Radeon X1000系列GPU的像素着色器来加速视频编解码,包括视频编码过程中的4∶2∶2至4∶2∶0转换、噪声消除、逆3∶2PD矫正、反交错,还包括视频回放过程中的反交错、格式转换、块消除和后期处理等等。随着DirectX 10时代的到来,会有越来越多的视频处理可以由GPU来完成。这可以说是目前GPGPU最成熟、最广泛的一种应用,也是我们最常接触到的广义GPGPU
既然GPGPU可以应用到视频处理上,那么GPGPU是否可以应用到音频处理上呢?答案是肯定的。英国剑桥大学的一个小组曾经宣布它们的音频视频交换(Audio Video Exchange)技术可以把音频数据转换成图形数据交由GPU处理,然后再将GPU处理的数据读出,并解释成音频数据播放出来。NVIDIA也表示过这一应用是可行的。但由于种种原因,该项目似乎没有了下文,进度不明。
既然GPGPU能够从CPU那里夺来视频处理的任务,目前正渐入佳境的物理加速当然也少不了GPGPU。发布首款PhysX物理处理器(PPU)的AGEIA公司认为,GPU和PPU应该各自独立负责图形运算和物理加速。不过NVIDIA和AMD显然不这样看,PPU和GPU相互独立,在3D渲染计算量大的时候,PPU就会浪费;碰到物理计算量大的时候,GPU就浪费了。因此完全可以在对GPU做少量改动的情况下,让GPU来完成PPU的工作,并且可以实时负载动态调整,达到性能的最优化。AMD在去年的台北Computex上就展示了基于CrossFire系统的物理加速方案,当一个系统中有三块显卡时,可以使用其中一块显卡专门负责物理计算,而另外两块显卡负责图形渲染,即“2+1”模式;如果系统中有两块显卡,则一块负责物理计算,一块负责图形渲染,即“1+1”模式。NVIDIA同样也在SLI平台上实现了“1+1”模式的物理加速方案,而且两家公司都声称GPU加速物理运算的速度远超PPU。在DirectX 10时代,统一着色构架的采用,完全可以让GPU进一步加入物理计算引擎,让物理处理和顶点处理、像素处理、几何处理共享统一着色器。事实上,NVIDIA宣称G80中已经加入了Quantum Effects技术来进行物理加速,究竟效果如何,让我们拭目以待。 #p#page_title#e#
当然,除了上述这些我们能看得到的应用,科学计算才是GPGPU真正的目标。它强大的浮点运算能力,很适合用来加速通用的矩阵计算,早期发表的GPGPU论文中,也大多是这种类型。其中,最引人注目的就是对流体力学的模拟。众所周知,流体力学的模拟十分复杂而且计算量大得惊人,用CPU来处理,既费时又费力,要达到实时绘制更是天方夜谭。为了提供足够的模拟计算能力,纽约一所大学的研究所使用了30颗GPGPU的集群,终于基本实现了流体物理现象的实时模拟和绘制。
B8.jpg
B9.jpg
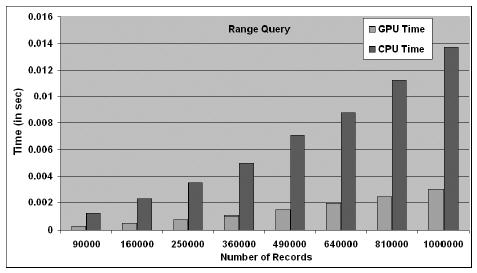
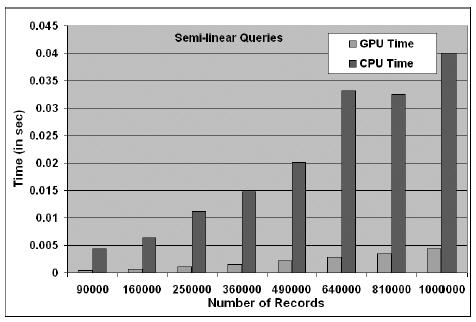
执行相同的半线性查询,GPU只需要CPU的十分之一时间就够了;而执行范围查询,GPU也只需要CPU的五分之一时间而已,可见GPGPU应用于数据库领域的优势
除了物理现象的模拟之外,GPGPU同样在数据库处理领域取得了很好的进展。数据库中最重要的一个操作就是对已有记录进行查询,它包括关系查询(Relational Query)、合取查询(Conjunction Query)和范围查询(Range Query)等。在GPGPU中,我们可以把一个个像素当作是数据项,而用纹理来表示数据项的各个属性,通过像素着色程序就可以对数据项的各种属性进行访问和操作。美国北卡罗莱纳大学曾经做过数据库查询操作的对比实验,一组是在NVIDIA GeForce 5900上,另一组是在Intel双路Xeon系统上。结果在几乎所有的实验中,都是GeForce 5900的运行性能远远优于双路Xeon系统,可见两者的数据库查询性能与它们的价格成反比。
B10.jpg
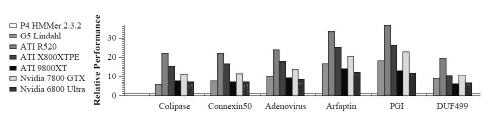
HMM搜索计算的性能对比
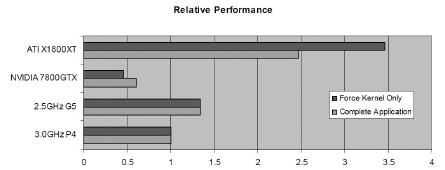
蛋白质折叠计算的性能对比
AMD、NVIDIA加速研发GPGPU
由于巨大的商业价值,目前AMD和NVIDIA等巨头都在加速研发GPGPU。
在2006年底的超级计算机大会上,AMD发布了业界首款“流处理器”(Stream Processor),专为工作站和服务器等纯计算系统而设计,适用于金融分析、地震偏移分析、生命科学等应用领域。这款“流处理器”其实就是基于Radeon X1900显卡(R580)开发设计的。在实际性能方面,尽管它具有375Gflops的浮点运算能力和64GB/s的存储带宽,但运行Folding@Home分布式通用运算时,它的速度只比AMD Opteron 180双核处理器50%左右,同时耗电量也更大。可以说这只是一款GPGPU“雏形”,还远未发挥出GPGPU的真正威力。
在运行Folding@Home分布式通用运算时,Radeon X1900比Opteron 180快50%
NVIDIA则在G80上使用了CUDA(Compute Unified Device Architecture,统一计算设备架构),并在G80上集成了为通用计算而设计的缓存,让128个统一着色器能够协同进行复杂的计算,同时还加入C编译器,使GPU如虎添翼。此外,NVIDIA也联合Adobe宣布,Adobe Acrobat 8和Adobe Reader 8软件可以使用GPU来进行2D加速,能大幅度加快PDF文档的浏览速度,今后在打开和翻页大容量PDF文件时就不会像现在这么慢了。
当然,GPGPU的研发也并非一帆风顺。除了GPU本身在发展时要解决耗电量过大和提高频率的瓶颈问题,GPGPU在体系结构的设计上还有什么特殊要求呢?首先在在动态流控制设计和实现方面,通用计算毕竟与图形运算不同,如果GPU对图形运算在动态流控制上做了过多的优化,就会降低通用计算的灵活性,可谓鱼与熊掌不可兼得。此外,GPGPU要同时处理多种类型的任务时,就会存在GPU资源的竞争问题,在任务之间如何仲裁非常关键,处理不好就会适得其反。例如当GeForce 8800要同时处理3D渲染和物理计算时,如何仲裁和分配资源才能达到最好的性能?这个问题肯定需要软硬件工程师的共同努力才能找到较好的平衡点。
GPGPU会取代CPU吗?
随着GPU的日渐强大,GPGPU也开始获得越来越广泛的应用。那么,会不会有一天GPGPU的计算能力和灵活性都超越了CPU,届时CPU何去何从?其实,早在2004年的SIGGRAPH图形大会上,就有科研人员在GPGPU论坛上预测,六年之内就出现CPU和GPU整合在一起的产品。这在当时来说无疑太过惊人,不过在AMD收购ATI之后,情况则发生了大逆转。AMD已经计划提供完整的计算平台,并打算在其制程转向45nm的时候,实现CPU和GPU的整合,两者不需要再单独存在。因此最终的情形可能不是谁会取代谁,而将诞生兼有图形计算和通用计算的统一处理器。也许,它会被称为无所不能的XPU(X处理器)。


