






Llama-2 LLM的所有版本和硬件配置要求
探索模型的所有版本及其文件格式(如 GGML、GPTQ 和 HF),并了解本地推理的硬件要求。
Meta 推出了其 Llama-2 系列语言模型,其版本大小从 7 亿到 700 亿个参数不等。这些模型,尤其是以聊天为中心的模型,与其他开源选项相比表现令人印象深刻,甚至在有用性方面与 ChatGPT 等一些闭源模型相媲美。
该架构基于优化的变压器设置,并使用监督技术和人工反馈对模型进行微调。他们在一个庞大的数据集上进行训练,该数据集不包括来自 Meta 的任何用户特定数据。
关于Llama 2
Llama-2 是指一系列预先训练和微调的大型语言模型 (LLM),其规模高达 700 亿个参数。
Llama 2 使用来自公开在线资料的更大数据集进行了初始训练阶段,超过了其前身 LLaMA(1) 使用的数据集大小。在这个预训练阶段之后,Llama-2 Chat是通过监督微调过程开发的,在此期间,人类专家为训练过程做出了贡献。
为了提高模型的性能并产生更自然的响应,下一阶段涉及从人类反馈中强化学习 (RLHF)。这种方法涉及一个迭代的细化过程,通过强化学习算法和人类反馈的整合来不断改进模型。
Llama 2 系列包括以下型号尺寸:
7B
13B
70B
Llama 2 LLM 也基于 Google 的 Transformer 架构,但与原始 Llama 模型相比进行了一些优化。例如,这些包括:
GPT-3 启发了 RMSNorm 的预归一化,
受 Google PaLM 启发的 SwiGLU 激活功能,
多查询注意力,而不是多头注意力
受 GPT Neo 启发的旋转位置嵌入 (RoPE)。
Llama 2 和 Llama 之间的主要区别是:
更大的上下文长度(4,096 个而不是 2,048 个令牌)
在更大的数据集上训练
在两个较大的 Llama-2 模型中,分组查询注意力 (GQA) 而不是多查询注意力 (MQA)。
Llama-2 是开源的吗?
根据开源促进会的定义,Llama 2 并不是完全开源的,因为它的许可证施加了与开源标准不一致的限制。该许可证限制了某些用户和目的的商业用途,特别提到每月活跃用户超过 7 亿的服务必须寻求单独的许可证,可能不包括主要的云提供商。此外,Llama 2 可接受使用政策禁止将模型用于非法或恶意目的,这虽然可以理解,但与不受限制使用的开源原则不同。
什么是Code Llama?
Code Llama 是 Llama-2 语言模型的变体,专为编码相关任务量身定制。它能够生成和完成代码,以及检测各种流行编程语言(如 Python、C++、Java、PHP、JavaScript/TypeScript、C# 和 Bash)中的错误。Meta 提供三种不同型号尺寸的 Code Lama:7B、13B 和 34B,以满足不同级别的复杂性和性能要求。
硬件要求
Llama-2 模型的性能很大程度上取决于它运行的硬件。 有关顺利处理 Llama-2 模型的最佳计算机硬件配置的建议, 查看本指南:运行 LLaMA 和 LLama-2 模型的最佳计算机。
以下是 4 位量化的 Llama-2 硬件要求:
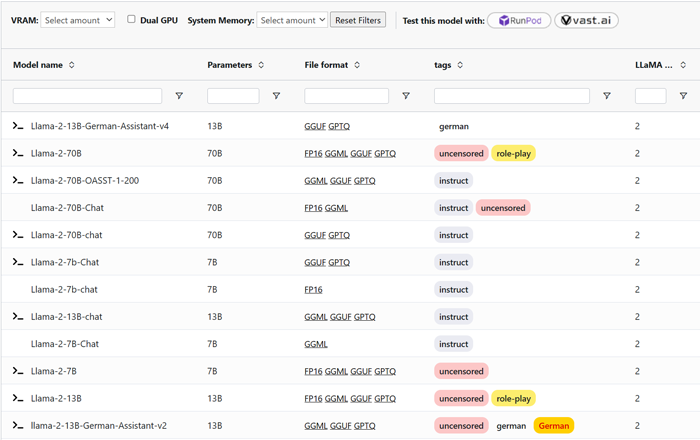
对于7B参数模型
如果 7B Llama-2-13B-German-Assistant-v4-GPTQ 模型是你所追求的,你必须从两个方面考虑硬件。第一 对于 GPTQ 版本,您需要一个至少具有 6GB VRAM 的体面 GPU。GTX 1660 或 2060、AMD 5700 XT 或 RTX 3050 或 3060 都可以很好地工作。 但对于 GGML / GGUF 格式,更多的是拥有足够的 RAM。您需要大约 4 场免费演出才能顺利运行。
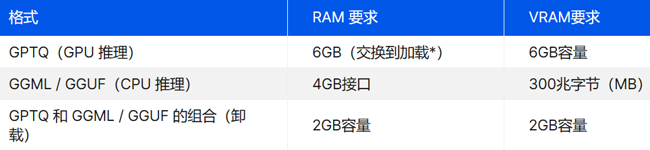
对于 13B 参数模型
对于像 Llama-2-13B-German-Assistant-v4-GPTQ 这样更强大的型号,您需要更强大的硬件。 如果您使用的是 GPTQ 版本,则需要一个具有至少 10 GB VRAM 的强大 GPU。AMD 6900 XT、RTX 2060 12GB、RTX 3060 12GB 或 RTX 3080 可以解决问题。 对于 CPU 入侵 (GGML / GGUF) 格式,拥有足够的 RAM 是关键。您需要您的系统有大约 8 个演出可用来平稳运行。
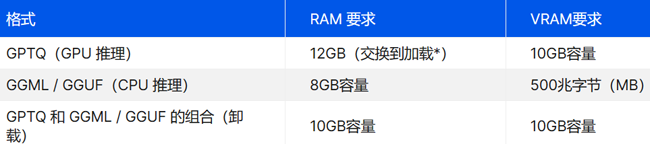
适用于 65B 和 70B 参数模型
当您升级到 65B 和 70B 型号()等大型型号时,您需要一些严肃的硬件。 对于 GPU 推理和 GPTQ 格式,您需要一个具有至少 40GB VRAM 的顶级 GPU。我们说的是 A100 40GB、双 RTX 3090 或 4090、A40、RTX A6000 或 8000。您还需要 64GB 的系统 RAM。 对于 GGML / GGUF CPU 推理,为 65B 和 70B 型号提供大约 40GB 的 RAM。
内存速度
运行 Llama-2 AI 模型时,您必须注意 RAM 带宽和 mdodel 大小如何影响推理速度。这些大型语言模型需要完全加载到 RAM 或 VRAM,每次它们生成新令牌(一段文本)时。例如,一个 4 位 13B 十亿参数的 Llama-2 模型占用大约 7.5GB 的 RAM。
因此,如果您的 RAM 带宽为 50 GBps(DDR4-3200 和 Ryzen 5 5600X),您每秒可以生成大约 6 个令牌。 但是对于像每秒 11 个令牌这样的快速速度,您需要更多带宽 - DDR5-5600,大约 90 GBps。作为参考,像 Nvidia RTX 3090 这样的高端 GPU 有大约 930 GBps 的 带宽到他们的 VRAM。最新的 DDR5 RAM 可提供高达 100GB/s 的速度。因此,了解带宽是有效运行像 Llama-2 这样的模型的关键。
建议:
为获得最佳性能:选择配备高端 GPU(如 NVIDIA 最新的 RTX 3090 或 RTX 4090)或双 GPU 设置的机器,以适应最大的型号(65B 和 70B)。具有足够 RAM(最小 16 GB,但最好为 64 GB)的系统将是最佳选择。
对于预算限制:如果您受到预算的限制,请专注于适合系统RAM的Llama-2 GGML / GGUF模型。请记住,虽然您可以将一些权重卸载到系统 RAM,但这样做会以性能为代价。
请记住,这些是建议,实际性能将取决于几个因素,包括特定任务、模型实现和其他系统流程。
CPU 要求
为获得最佳性能,建议使用现代多核 CPU。第 7 代以上的 Intel Core i8 或第 5 代以上的 AMD Ryzen 3 将运行良好。 具有 6 核或 8 核的 CPU 是理想的选择。更高的时钟速度也改善了即时处理,因此请以 3.6GHz 或更高为目标。
拥有 AVX、AVX2、AVX-512 等 CPU 指令集可以进一步提高性能(如果可用)。关键是要有一个相当现代的消费级CPU,具有不错的内核数量和时钟。 以及通过 AVX2 进行的基线向量处理(使用 llama.cpp 进行 CPU 推理所必需)。有了这些规格,CPU 应该可以处理 Llama-2 模型大小。
人工智能训练与推理工作站、服务器、集群硬件配置推荐
上述所有配置,代表最新硬件架构,同时保证是最完美,最快,如有不符,可直接退货
欲咨询机器处理速度如何、技术咨询、索取详细技术方案,提供远程测试,请联系
UltraLAB图形工作站供货商:
西安坤隆计算机科技有限公司
国内知名高端定制图形工作站厂家
业务电话:400-705-6800
咨询微信号:



