






引领行业发展 NVIDIA谈GPU与高性能计算
美国时间2012年11月12-15日,著名的Super Computing 12大会在犹他州盐湖城举行。本次SC12大会上,发布了最新的TOP500排名,来自美国能源部橡树岭国家实验室的“泰坦Titan”获得了第一名的殊荣。据悉,泰坦采用了18688颗NVIDIA Tesla K20 GPU加速芯片,这些芯片所提供的性能占总性能的90%,也是其夺冠的关键。在SC12大会上,我们有幸采访到了NVIDIA Tesla事业部的总经理Sumit Gupta先生,他将详细为我们介绍NVIDIA在高性能发展上的策略及泰坦相关的点点滴滴。

NVIDIA Tesla事业部的总经理Sumit Gupta先生
独步天下 NVIDIA领军GPGPU时代
谈到GPU,大家的第一印象就是我们电脑中的显卡。但随着计算能力的不断提高,GPU已经不仅仅局限于图形运算,在高性能计算领域,它更是作为加速芯片而存在。正是NVIDIA首次提出了GPGPU的概念,即通用计算处理单元,正是这一概念促成了高性能计算的飞速发展。
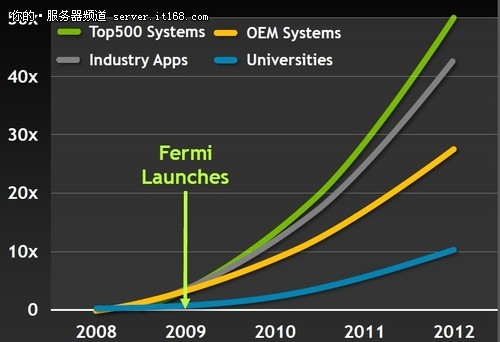
在GPU加速技术出现之前,超级计算机的发展非常缓慢,因为主要借助于CPU计算,因此也就收到了摩尔定律的制约。从图中就可以看到这种变化的趋势——在2009年NVIDIA Fermi架构芯片发布之后,高性能计算出现了爆炸式的增长,性能提升达到了数十倍。以国内超算的发展为例:2008年,国内顶级的曙光5000A超级计算机每秒运行速度为250万亿次,那时的超算还停留在百万亿次时代;但是到了2010年,国产天河一号A荣膺TOP500冠军,每秒运行速度达到2507万亿次。2年的时间性能提升十倍,跨入了千万亿次时代。可以说,正是由于GPGPU的出现,使得超算的性能迅速提升,同时也节约了大量的场地、电力、维护等成本。从这个意义来说,NVIDIA提供了一个可以永载史册的创举。
Tesla K20X/K20助力Titan(泰坦)系统荣膺TOP500冠军

在谈到GPU运算加速的时候,Sumit Gupta先生认为——目前近乎所有的超级计算机都采用了GPU加速的方式,这已经是大势所趋。例如本次TOP500第一名Titan(泰坦),它由2009年最快的超级计算机Jaguar美洲豹升级而来,正是NVIDIA Tesla K20 GPU加速芯片提供了如此强大的性能。如果仅仅依靠CPU进行计算的话,不仅仅需要更大面积的计算机集群,其耗电量也会相当惊人(大约相当于6-8万户居民的年耗电量),这是完全不可想象的事情。
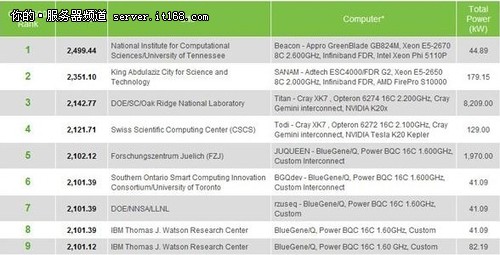
同时在谈到节能与功耗的时候,Sumit Gupta先生也谈到了最新的Green 500排名。超级计算机Titan(泰坦)在Green 500中排名第三,虽然并未获得第一,但是Titan是其中最大的系统,能够让如此巨大的系统达到良好的节能效果也是非常难得,也从侧面反映出Tesla K20 GPU加速芯片的节能性。
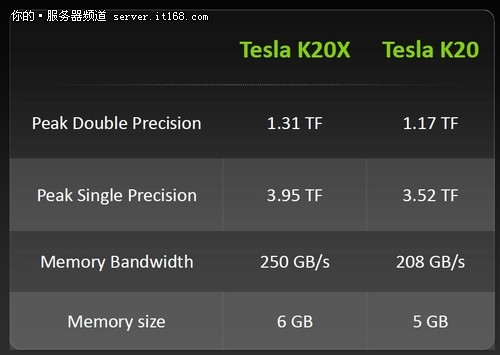
谈到世界上最快的超级计算机泰坦,就不能不谈到NVIDIA Tesla Kepler K20芯片。在这一代的Kepler家族中包括了 K20和K20X两款芯片,也是目前NVIDIA速度最快的芯片,两者的区别在于规格的不同,K20X的版本更高一些。具体说来,本次泰坦使用的K20芯片可以提供3.52TF的单精度浮点性能和1.17TF双精度浮点性能,显存容量为5GB,带宽为208GB/s。相比上一代的Fermi产品来说,同样平台下Kepler K20的实测效率可以达到2.25TF,芯片利用率为76%;上一代的Fermi芯片利用率只有61%。
这里我们有必要就带宽问题进行一个说明——不久前,英特尔发布了最新的至强融核(Xeon Phi)协处理器,其标称带宽高达300MB/s,也可以算是目前Tesla产品强劲的竞争对手。不过对此,Sumit Gupta先生认为理论带宽只是产品的硬件规格标准,具体的计算能力还应该在应用中体现。并且即使从硬件规格的角度上看,通过诸多用户的测试发现,Kepler K20与Xeon Phi在实际应用中的表现相当,这是因为Kepler K20的带宽利用率可以达到70%以上,而Xeon Phi根据STREAM 基准测试的结果显示也只有50%的带宽利用率。因此,事实上来两者的有效带宽不相伯仲,不能单纯依靠理论带宽来判断产品的性能优劣,一切都应该从实际的应用出发。 #p#page_title#e#
CUDA编程的应用与优势
GPGPU的快速发展,一方面是由于硬件配置的强大,但更多还是得益于CUDA编程的便捷与高效。目前CUDA在全球范围内的62个国家、近630所大学都有相关的合作, 并且有超过8000个开发机构、超过150万次的软件下载率。以最新的Tesla K20X/K20芯片为例,包括橡树岭国家实验室、瑞士国家超级计算中心以及中国上海交通大学等31个科研机构和大学都采用了这款世界最快的产品,这也帮助他们在ANSYS Fluent (计算流体动力学)、MSC Nastran (结构力学)和CHARMM (生命科学)等多个关键的科研领域获得了突破。
现场,笔者就CUDA产品的编程易用性问题与Sumit Gupta先生进行了交流。对于异构计算的应用来说,编程是至关重要的工作,而是否易于编程则直接关系到了用户的应用能否正常运行。Sumit Gupta先生通过一个实例详细而直观的解释了CUDA编程的优势与便捷性。

Sumit Gupta先生谈到,如果按照标准的C语言编程,一个简单的计算案例需要进行一步步的顺序计算,会需要大量的时间。而在通过CUDA编程之后,只需要加入几个简单的关键性语句,就可以实现快速并行计算,大大缩减计算时间,提升效率。总结起来,CUDA编程只是基于原有的C、C++等语言进行编译,并不需要改变语言本身,具备了上手简单、操作便捷等优势。
关于Tesla K20X/K20的其他问题
记得在Fermi时代,NVIDIA曾在平衡产品性能与良品率时有过困扰,那么对于新一代的Kepler芯片来说,是否还会有这样的困扰呢?Sumit Gupta先生表示之前Fermi的问题的确非常棘手,当时NVIDIA只能保证高端的Tesla供货。但目前Kepler芯片目前产能充足,一次性供应Titan多达18000颗芯片就很能说明问题。而且Kepler经过了在GeForce产品中的测试,良品率非常高,目前在Tesla供货方面毫无压力。

笔者与Sumit Gupta先生合影
谈到CUDA普及化教育的问题,NVIDIA表示长期以来一直与国内外许多大学保持着良好的合作关系,从师资力量的培养和学员的教育方面都提供了大力的支持。就国内来说,所有开设并行课程的高校也都提供了CUDA课程,而且在今年9月NVIDIA也与浪潮集团联合发布了“GPU卓越人才计划”,打造中国ICCE(Inspur NVIDIA CUDA CERTIFIED ENGINEER)技术应用工程师认证第一品牌,从而进一步推动中国GPU应用的发展。
如今,谈到高性能计算或者超级计算机,已经不仅仅是单纯的CPU计算,因为随着计算性能和应用需求的不断发展,任何单纯的CPU计算都被证明是不可行的,传统意义上依靠大量CPU计算节点和大规模供电的时代已经是一去不复返了。正是NVIDIA对于GPGPU的推广,让行业迅速进入到了异构计算的时代,从而不再仅仅依靠CPU提供所有的计算能力。
将运算需求按照不同的类型进行划分,为每一种处理器选择最佳的计算内容,这就是异构计算的魅力。异构计算已经成为了行业发展的大势所趋,NVIDIA在推动行业发展和促进人才培养的方向上功不可没。未来,NVIDIA还将继续拓展异构计算业务,争取将高性能计算,特别是国内的高性能计算应用推向普及。


