






Supercomputing2009国际会议见闻
2009 年11 月16 日,我们从北京出发,前往洛杉矶再转飞波特兰,参加2009supercomputing 国际会议,由于我们只注册了参展商,只能在展览区活动,不能去参加技术类讲座。但这也使我们有足够的时间了解国际顶尖公司在高性能计算机系统方面的最新研究进展。以下总结几点体会:
1. Intel业界的领袖地位再次得到体现
展览会上,Intel公司具有很大的展台,在展台上安排Intel自己和合作厂商的技术讲座了,每半小时一个,内容丰富。Intel还组织了一个Tour,由Intel的导游带领参观者前往七个Intel公司的合作厂商的展台上参观,这些合作厂商都是采用Intel处理器设计服务器的系统厂商。
最有代表性的是SuperMicro,他采用Intel Nehalem处理器设计了世界上密度最高的风冷刀片系统,在7U的空间内,可以放置两层共20个双路刀片。产品具备高能效的电源(转换效率达94%),以及低噪音设计,在配备10个双路刀片节点时运行的噪音不大于50分贝。

很多1U 服务器采用双路twin 设计,实现1U4P 解决方案。或2U 双twin 设计,实现2U8P解决方案,还有在1U 空间里安置1 个双路服务器和两块GPU 卡的设计。

1U2P+2 GPU
由于Intel Nehalem CPU 的推出,使得Intel 与AMD 的技术路线趋于一致,导致构造多处理器系统的设计简化,访存性能和互联性能增强,再加上Intel CPU 在主频和功耗方面的优势,使得Intel 的老大地位进一部得到加强
2. IBM 把高性能计算机的结构和工艺做到了极致
展会上IBM 展出了基于Power7 CPU 的256 路CC-NUMA 系统。在2U 空间内布放256 个核,单机箱的计算能力达到8Tflops,功耗10KW。

该系统包括8 个CPU 模块,每个模块都是4CPU 封装在一起的MCM,同一MCM 上的4个CPU 间采用全互联结构,不同MCM 之间也采用全互连结构,每个MCM 连接一个HUB芯片,HUB 芯片输出PCI-E GEN2 I/O 接口和机箱间扩展
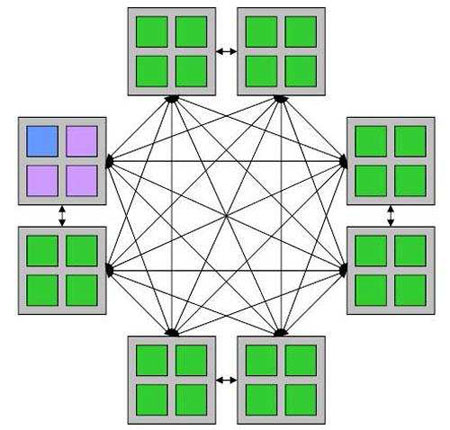
Power7 系统拓扑

IBM Power7 MCM
Power7 系统的内存也采用专用设计,在每个内存子卡上都有两片高速信号适配芯片。在系统后面有128 个扩展光纤接口,可以与其他系统直连实现规模扩展。
Power7 大容量的L3 通过内部互联结构连接,据说处理器核心互联的带宽达到了500GB/s,经过了大容量L3(L4)的筛选之后,仍然需要大量的内存带宽,Power7 提供了两个DDR3内存控制器,每个控制器支持4 个DDR3 通道,大约支持到主流水准:DDR3-1600,这样内存控制器可以提供100GB/s 的带宽。为了更好地支持多个内存通道,并提高性能,Power7
每个内存控制器都具有16KB 的重调度缓存来重新排序内存存取请求。
Power7 的一个重点是多路处理器,Power7 实现了SMP 的硬件一致性处理。Power7 通过三个方面的设计来达到32 路SMP 能力:巨大的带宽、特别的拓扑结构和特别的一致性协议。Power7 的处理器间总线可以提供360GB/s 的带宽。
Power7 使用了一个两层的拓扑模型:4 个处理器组成一个本地SMP 组(需要7 个本地I/O 总线),然后8 个SMP 组之间两两直接互联(每个SMP 组需要7 个外部I/O 总线),为了实现这个目标,Power7 提供了两个总线:一个用于本地SMP,一个用于远程SMP。总线的位宽是120Byte。
此外为了支持这个拓扑结构,Power7 的一致性协议混合了两种一致性消息的广播方法:
一种是全局广播,一种是本地SMP 组的猜测性广播。这个一致性协议定义了13 种状态(Nehalem 使用的MOESI 是5种),并通过缓存线上额外的设置位,Power7 最终实现了复杂的结构,在32 路处理器、8 核心、总共256 个处理内核的SMP 系统里,可以同时维持20000个缓存一致性操作。
该系统的高度为2U,长度大约是1.5m,宽度大约是1m。非常壮观。在这一个箱子内就有256 个CPU 核。8 核4CPUX8MCM=256 核。整个系统支持Cache 一致性。
系统具有16 个PCI-E GEN2 16X I/O 接口,可以连接GPU、Fiber Channel、Infiniband 等设备。 #p#page_title#e#
最与众不同的是该系统的水冷散热设计,CPU 模块、I/O HUB、内存、电源都有散热水管直接连接在相应的散热器上,在集中在机箱两侧的主水管,与机箱外的循环系统连接。
IBM Blue Gen 的结构是高密度风冷组装技术的典型代表。

Blue Gen 组装技术

IBM Roadrunner节点
3. CRAY 采用传统技术构造全球最快的超级计算机系统
本次会议上Cray 公司的Jaguar 以1.75petaflop/s 的运算速度位居第一,超过了原先排在第一位的IBM “Roadrunner"。Jaguar 使用的是AMD Magny-Cours 核心六核Opteron 处理器。

Cray XT5主板
说Cray 采用传统技术,是指其系统结构、互连技术、系统组装和散热等方面相对其前几代产品,没有本质上的差异。体系结构仍然是MPP,互连网络拓扑仍然采用3D-torus,互连芯片仍是具有一个连接CPU 的HT 端口和6 个3 维连接端口的Seastar 芯片,互连带宽也没有增加。与Cray 的技术人员交流过程中,他们近期还没有采用Intel Nehalem CPU的计划,仍会继续使用AMD Opteron处理器来构造超级计算机。通过更换核心更多的CPU,提高系统的计算能力,可以很好的实现系统性能和成本之间的平衡。

Cray 另一个重点的宣传的是个人超级计算机产品,在机箱上喷涂了绿草、蓝天和白云,重点强调绿色、环保的概念。其系统还是典型的Cluster,最多可配置8 块双CPU 刀片,系统内置千兆以太网交换机,也可配置Infiniband 交换机,所有互联网络的连线都是外置,从背后看有些乱。系统配置4 个电源模块,实现2+2 冗余,整机功耗小于2KW。噪音小于50db。
4. SGI 继续其cc-NUMA 之路
本次展会上SGI 公司展出了采用Intel Nehalem CPU 的cc-NUMA 系统,这是SGI cc-NUMA 系统第三次更换处理器,
其前两代分别采用MIPS 和Itanlium 处理器,由此可以看到Itanlium 处理器后续产品计划可能有所调整,因为按照Intel
的原计划,本来Tukwila 应该在今年发布。
另外SGI 还展出了一些存储系统。从总体上看,SGI 在图形领域的优势已经被Nvidia 远远地抛在了后面,某种意义上,
SGI 已经成为通常的服务器和存储系统提供商,但其cc-NUMA系统还是有一定特色。

5. SUN专注于Storage 和Server
Sun 公司被Oracle 收购后,其业务方向受到了一定的影响,从展会上看,其重点集中在Storage和Server 两个方面,而CPU 业务被淡化。最有特色的是SUN 设计了一款采用Flash 芯片的Storage,在1U 机箱内布满了Flash 存储卡,通过PCI-E 接口连接服务器。
印象比较深的是Sun 公司的服务器结构设计,工艺精良,结构合理,可以做为我们学习的榜样。

SUN Flash Array

SUN Server
6. Fujitsu 的Petascale 系统原型
Fujitsu 公司设计了Sparc VIIIFX CPU,该CPU 具有8 个核心,Die size 大约20mmX20mm,同时设计自己3D-Torus 互连芯片,其节点结构与Cray XT5 很类似,但是采用水冷散热,在一个机柜内,分上下两部分分别水平安装12 个4P 节点板,中间是I/O 和电源,散热水管从每个节点板的前面连接到机柜侧面的主管道上。

Fujitsu PetaScale SystemBoard
系统拓扑结构采用多维Mesh/Torus 结构。一个Rack 内的12 节点连成立方体,再以12个节点为一个大节点,连成更大的3D-torus 网络。这样推算,每个互连芯片至少需要10 个端口,其中4 个用于连接大节点内的其他相邻芯片,其余6 个用于连接其他大节点的互连芯片。
这种拓扑结构相比Cray 的3D-torus 复杂,但网络跳步较少,等分带宽高,相对于多级互连网络,较易实现,也方便扩展。

Multidimensional mesh/torus Interconnection Networks

System Rack
7. 高性能互连网络
高性能互连网络最抢眼的的是Mellanox 公司的Infiniband 网络,其40Gbps 网络产品已经成熟,并在高性能计算机系统中获得应用,如SuperMicro 的刀片系统就采用了Mellanox的40Gbps Infiniband。 #p#page_title#e#
Myricom 公司的网络已经少有人问津,他们的产品已经转向到10G 以太网上。
采用六类铜缆标准的10G 以太网交换机和网卡已经成熟,但价格还是制约其在高性能计算机系统中应用的最大障碍。
光模块的性能越来越高,Avago 公司的12 路,每路10Gbps 的光收发模块已经商品化。
8. GPU加速
本次会议上GPU 加速也是一大亮点,天河一号系统依靠GPU 加速部件位居top500 第五位。很多服务器厂商都有专有的GPU 加速服务器设计,如前面提到的1U2P+2GPU 卡系统。
IBM Power7 系统的I/O 扩展槽也可以插GPU 卡。
最有意思的是一家爱好者,采用手工打造了具有8 个GPU 卡的高性能计算系统,并移植了Fortran 语言编译器。
Nvidia 公司租了很大的展位,并安排了多场专题技术讲座,看得出他们推广GPU 计算的信心和力度。
9. 高性能计算应用研究多集中在国家实验室大学和研究所
10. 参展单位分布
参展单位以美国公司、大学、研究所居多,日本公司和研究所也占据了很多展位,台湾工研院和高性能计算中心也有展位,并安排了介绍性讲座。计算所弄了大陆地区唯一一个展位,显得很单薄。


