






CUDA:一种在GPU上进行计算的新架构
它是我们迫切需要的新颖的硬件和编程模型,能让GPU的计算能力得以完全发挥,并将GPU暴露为一种真正通用的数据并行计算设备。
CUDA表示Compute Unified Device Architecture(统一计算设备架构),是NVIDIA为自家的GPU编写了一套编译器及相关的库文件。作为一种新型的硬件和软件架构,用于将GPU上作为数据并行计算设备在GPU上进行计算的发放和管理,而无需将其映射到图像API。

|
|
CUDA可用于GeForce 8系列、Tesla解决方案和一些Quadro解决方案,操作系统的多任务机制负责管理多个并发运行的CUDA和图像应用程序对GPU的访问。
CUDA采用C语言作为编程语言提供大量的高性能计算指令开发能力,使开发者能够在GPU的强大计算能力的基础上建立起一种效率更高的密集数据计算解决方案。CUDA是业界的首款并行运算语言,而且其非常普及化,目前有高达8千万的PC用户可以支持该语言。
CUDA的特色如下,引自NVIDIA的官方说明:
1、为并行计算设计的统一硬件软件架构。有可能在G80系列上得到发挥。
2、在GPU内部实现数据缓存和多线程管理。这个强,思路有些类似于XB360 PS3上的CPU编程。
3、在GPU上可以使用标准C语言进行编写。
4、标准离散FFT库和BLAS基本线性代数计算库。
5、一套CUDA计算驱动。
6、提供从CPU到GPU的加速数据上传性能。瓶颈就在于此。
7、CUDA驱动可以和OpenGL DirectX驱动交互操作。这强,估计也可以直接操作渲染管线。
8、与SLI配合实现多硬件核心并行计算。
9、同时支持Linux和Windows。
◆ CUDA:主导GPU计算的革命

GPU超强的计算能力让它在通用计算领域大有可为,而CUDA则让它变成可能,简单易用的开发环境让CUDA主导起GPU计算的革命。
正如NVIDIA首席科学家David Kirk所说:“我认为CUDA已经取得了空前成功,它的接受程度令人吃惊。这也表明了人们希望对整台电脑进行编程的浓厚兴趣。过去人们往往是编写一个C程序来控制CPU,再编写一个图形程序来控制GPU。你一定想通过编写一个程序来控制CPU和GPU。因此我坚信,将来CUDA将变得无处不在。如果要对CPU和GPU进行编程并管理系统中的所有资源,那就没有理由不用CUDA。”
GPU正逐渐将并行计算推向主流,并行计算与异构处理器系统的“联姻”将是大势所趋。而主导这场变革的就是CUDA。随着越来越多的开发者加入到CUDA怀抱,支持CUDA的软件必将渗透到我们生活的方方面面,亿万次的计算能力是我们充满期待最好的诠释。
◆ CUDA的本质
CUDA的本质是,NVIDIA为自家的GPU编写了一套编译器NVCC极其相关的库文件。CUDA的应用程序扩展名可以选择是.cu,而不是.cpp等。
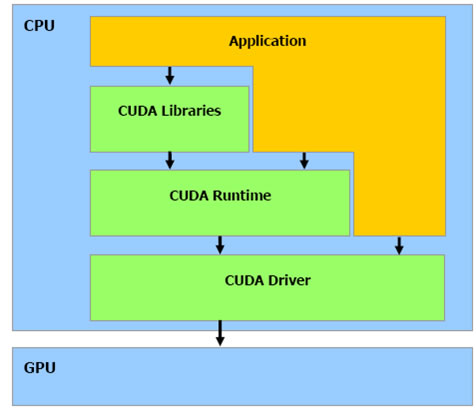
NVCC是一个预处理器和编译器的混合体。当遇到CUDA代码的时候,自动编译为GPU执行的代码,也就是生成调用CUDA Driver的代码。如果碰到Host C++代码,则调用平台自己的C++编译器进行编译,比如Visual Studio C++自己的Microsoft C++ Compiler。然后调用Linker把编译好的模块组合在一起,和CUDA库与标准CC++库链接成为最终的CUDA Application。由此可见,NVCC模仿了类似于GCC一样的通用编译器的工作原理(GCC编译CC++代码本质上就是调用cc和g++)。

CUDA在执行的时候是让host里面的一个一个的kernel按照线程网格(Grid)的概念在显卡硬件(GPU)上执行。每一个线程网格又可以包含多个线程块(block),每一个线程块中又可以包含多个线程(thread)。
以军队来打比方,每一个线程,就相当于每一个士兵,当要执行某一个大的军事任务的时候,大将军(Host)发布命令,把这次行动分解成一个一个的子任务(kernel_1,kernel_2……kernel_M),每个子任务由不同的统领(Grid)负责,各统领又把任务分成一部分一部分,划分给手下的小头目(Block),这些任务就由小头目下的士兵(Thread)去执行完成。 #p#page_title#e#
通过CUDA编程时,将GPU看作可以并行执行非常多个线程的计算设备(compute device)。它作为主CPU的协处理器或者主机(host)来运作:换句话说,在主机上运行的应用程序中数据并行的、计算密集的部分卸载到此设备上。
经过了CUDA对线程、线程块的定义和管理,在支持CUDA的GPU内部实际上已经成为了一个迷你网格计算系统。在内存访问方面,整个GPU可以支配的存储空间被分成了寄存器(Register)、全局内存(External DRAM)、共享内存(Parallel Data Cache)三大部分。其中寄存器和共享内存集成在GPU内部,拥有极高的速度,但容量很小。共享内存可以被同个线程块内的线程所共享,而全局内存则是我们熟知的显存,它在GPU外部,容量很大但速度较慢。经过多个级别的内存访问结构设计,CUDA已经可以提供让人满意的内存访问机制,而不是像传统GPGPU那样需要开发者自行定义。
在CUDA的帮助下普通程序员只要学习一点点额外的GPU架构知识,就能立刻用熟悉的C语言释放GPU恐怖的浮点运算能力,通过CUDA所能调度的运算力已经非常逼近万亿次浮点运算(GeForce 280GTX单卡浮点运算能力为933GF LOPS)。而在此之前要获得万亿次的计算能力至少需要购买价值几十万元的小型机。
CUDA支持的GPU (CUDA-enabled GPU)包含GeForce、Quadro和Tesla三个系列:GeForce是NVIDIA公司面向消费市场的GPU产品;Quadro是面向专业图形市场的GPU产品;而Tesla则是专门面向GPU计算的产品,它不具备图形输出的功能,因此不能作为图形卡来使用。这三个产品面向不同的应用领域,因此建议在开发和部署CUDA应用的时候需要考虑到产品的应用决定采用不同的GPU。
NVIDIA的CUDA-enabled GPU具有一个完整的产品线,各种用户都可以从中选择到合适自己的产品。对于有高密度计算能力需求的用户来说,Quadro和Tesla则是必须的选择。诸如Quadro Plex 1000 Model S4和Tesla S870在一个1U高度的标准服务器机架机箱内装备了四个GPU,每个GPU具备128个stream processor以及1.5GB的存储器,每个1U装置总共具备512个stream processor和6GB存储器,非常适合于有高密度、大规模数据计算需求的用户


