






个人超级计算机不再是空穴来风
每秒运算速度达4万亿次、只有台式机大小、售价不到8万元的个人超级计算机,是梦望还是现实?NVIDIA公司刚刚发布的Tesla个人超级计算机似乎正在让这一切成为可能。
11月18日,在美国2008年超级计算大会(SC08)上,NVIDIA公司正式发布了针对全球1500万名科学家和工程师的Tesla个人超级计算机新产品,要“让每个研究人员都可配备一台超级计算机”。NVIDIA 公司Tesla计算产品总经理Andy Walch先生通过电话会议方式接受了IT168服务器频道的采访。
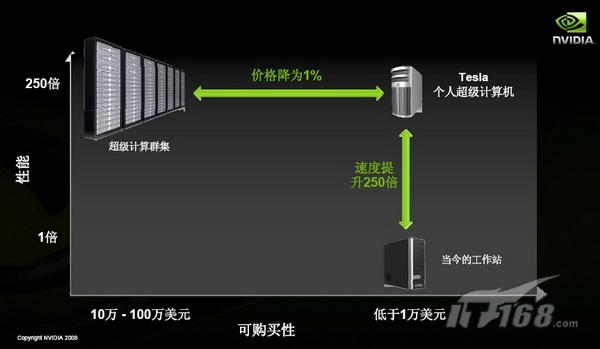
据介绍,Tesla个人超级计算机拥有“工作站的价格,超级计算机的性能,适合个人操作,非常简单易用”等几大特点。在外观上就如同一台可以放在桌面上的工作站一样,内置一颗四核CPU 和3-4个GPU单元模块,拥有12-16GB系统内存、1200-1350W电源,可以直接使用办公环境下标准的电源。由于总共拥有960个GPU核心,使其浮点计算性能高达每秒4万亿次,是当前台式工作站的250倍,而售价不到1万美元,跟相同性能水平的传统超级计算集群相比,价格只有1%。要知道,就在四年前,上海超级计算中心所采用的10万亿次超级计算机曙光4000A需要近亿元人民币,占地1/4个足球场。

性能提升 功耗降低 GPU计算有独到之处
Andy Walch介绍说,Tesla个人超级计算机实现了人们“以工作站的价格和占地空间获得超级计算集群性能”的梦想,开启了个人高性能计算的新领域。“就象20多年以来,PC从早期的专家设备变成了今天人手一台的普及工具一样,我们相信从现在开始,个人超级计算机也可以走向普及”.
目前,这类台式HPC产品已经在国外一些大学科研人员当中得到了采用。最早使用的是比利时安特卫普大学,该校原来用的超级计算机有512颗处理器核,成本是530万美元,由全校共享使用;后来换成一台拥有8个GPU的台式系统,性能相当,成本只有7000美元,而且可以为每个研究人员在桌边配备一台,不再为共享资源进行竞争。可见,无论是在性价比方面,还是在使用模式上都跟以前相比有了“革命性”的变化。据称,当前包括美国麻省理工学院、哈佛大学、伊利诺伊大学、英国剑桥大学、德国布伦瑞克里大学以及韩国延世大学都已经采用了3颗-16颗GPU不等的此类桌面系统。

全球高性能计算机TOP500排行榜的创始人之一、美国田纳西大学教授Jack Dongarra认为,“GPU的发展使得实际应用程序可以在GPU上轻松运行,并且速度远远超过多核系统。未来的计算架构将是并行核心GPU和多核CPU合作的混合系统。”CRAY公司前首席科学家Burton Smith也认为,NVIDIA的异构计算使“台式超级计算机”的突破成为可能。
实际上,在今年9月份,微软和Cray两家公司就首次联手推出了大小和普通PC相当,售价2.5万美元到6万美元以上,预装Windows HPC Server 2008操作系统的个人超级计算机Cray CX1。不过,跟NVIDIA采用的CPU与GPU混合架构不同,Cray CX1采用的是标准X86 CPU技术,支持多达8个节点、16个英特尔至强处理器、每节点64GB内存和4TB内置存储。
不过,Andy Walch表示,跟传统仅基于CPU的架构相比,CPU与GPU混合的架构在某些应用领域效率更高,数十倍甚至上百倍的性能提升正是GPU的最大优势。
Andy Walch举例说,在一项针对计算化学的应用测试中,如果仅使用CPU需要4.6天,而使用GPU仅仅需要27分钟,在神经医学建模方面,使用CPU需要2.7天,而使用GPU只需要30分钟,另外在医学成像、分子动力学、视频转码、Matlab计算、天体物理、金融模拟、线性代数、3D超声波、量子化学、基因排序等领域,一些大学和相关软件厂商的测试也证实了18倍到149倍不等的性能提升。

另外,在绿色节能方面,GPU系统也明显的优势。如NVIDIA最新推出的Tesla S1070与X86产品相比,每瓦特性能提升了18倍。“这对石油天然气勘探这类用户来说非常重要,因为他们需要进行大量的数据分析,服务器电耗极其惊人,使用GPU系统可以节省大量的电力成本。目前Tesla S1070已经在Hess、雪佛龙石油、巴西石油等公司得到了成功应用。” Andy Walch谈到。
CUDA发展良好 GUP计算生态圈初步形成
可见,虽然一般用户已经非常熟悉传统X86集群系统在HPC领域的使用模式,但是我们认为,CPU与GPU的混合系统也确实非常值得关注,用户可以根据自己的实际应用进行测试比较。不过,值得一提的是,CPU系统毕竟已经非常成熟,现有应用软件大多是针对CPU进行编写的,而用GPU进行高性能计算还是一个新兴的领域,特别是在GPU编程方面对于很多用户来说仍是非常大的挑战。
对此,NVIDIA公司表示,由于对GPU架构进行了根本性的改变,使其可以用C语言来编程,并推出了全球第一个针对GPU的并行编程环境CUDA,可以用于Windows及Linux。“CUDA在GPU多核并行计算中起到的作用就好比是军队里的将军一样,通过它来保证并行高效有序地实现。”跟CELL、FGPA以及其他GPU相比,CUDA环境支持已经成为NVIDIA GPU计算的一大优势,用户借助CUDA可以更加方便地使用GPU计算。
Andy Walch此番还透露了CUDA推出一年多来在全球的发展情况:NVIDIA已经在全球卖出了1亿颗以上支持CUDA的GPU产品,CUDA 开发人员超过了2.5万人,全世界有50多所大学开设了CUDA课程,包括中国科学院、清华大学等。GPU计算的生态系统已经形成。
由于NVIDIA广为人知的GPU产品是Geforce系列,虽然Geforce和Tesla都支持CUDA,但两者在产品设计和适用环境仍然存有非常大的区别。Andy Walch解释说,在产品设计上,Tesla的板载内存容量高达4GB,而Geforce只有1GB,前者可以大大减少数据传输量,可以实现更高的计算精度,另外前者由于针对企业级应用环境,在防烧毁等测试方面更加严格和全面。因此,对于一般性应用如视频解码、游戏等使用Geforce就可以,而对于科学计算应用如石油勘探、天气预报等,建议采用计算精度和可靠性更高的Tesla。
在SC08上,PGI、Mathematica等专业软件开发商演示了利用CUDA开发软件并获得性能极大提升的实例。NVIDIA还宣布,包括戴尔、华硕、NEC、Cray、布尔等合作伙伴后续将推出各自基于NVIDIA Tesla GPU处理器卡的个人HPC产品。
实际上,做个人高性能计算机的不仅仅是NVIDIA和Cray。早在2006年11月,泰安就在美国2006超级计算年会上推出了运算性能达256 GFLOPs的“TYPHOON台风”600系列个人超级计算机。早几年前,中科院计算所的李国杰院士也提出了“一万块钱购买一万亿次计算能力”的构想。到了2008年,在中科院计算所的支持下,曙光公司高调推出了pHPC100个人高性能计算机。在前不久举行的2008年全国高性能计算学术年会上,中国科技大学陈国良院士也做了关于pHPC的主题报告,个人高性能计算机的概念得到了英特尔、AMD、曙光、宝德、超微等与会公司的认同。另外,从去年开始,IBM、HP、英特尔等都推出了所谓针对成长型中小企业的刀片服务器产品——IBM BladeCenter S、HP BladeSystem C3000、英特尔模块化服务器,尽管没有挂“个人超级计算机”的名头,但高性能计算却是这些产品的目标市场之一。由此可见,个人HPC早已经不再是一个空穴来风的概念,而是已经涌现出了许多实实在在的产品,高性能计算普及的梦想已经不再遥不可及。


