






基于GPU的数字图像并行处理研究
GPU并行化处理
可编程图形处理器(Programmable Graphic Process Unit, PGPU)是目前计算机上普遍采用的图形图像处理专用器件,具有单指令流多数据流(SIMD)的并行处理特性,而且提供了完全支持向量操作指令和符合IEEE32位浮点格式的顶点处理能力和像素处理能力,已经成为了一个强大的并行计算单元。研究人员将其应用于加速科学计算和可视化应用程序,取得了令人鼓舞的研究成果。
与CPU相比,GPU具有以下优势:强大的并行处理能力和高效率的数据传输能力[1] [2] [7]。其中,并行性主要体现了指令级、数据级和任务级三个层次。高效率的数据传输主要体现在两个方面: GPU与显存之间的带宽为:16GB/s;系统内存到显存的带宽为:4GB/s。
总上所述,GPU比较适合处理具有下面特性的应用程序:1、大数据量;2、高并行性;3、低数据耦合;4、高计算密度;5、与CPU交互比较少。
数字图像处理的并行化分析
数字图像处理算法多种多样,但从数据处理的层面来考虑,可以分为:像素级处理、特征级处理和目标级处理三个层次[3][4]。
(1)像素级图像处理
像素级处理,即由一幅像素图像产生另一幅像素图像,处理数据大部分是几何的、规则的和局部的。根据处理过程中的数据相关性,像素级处理又可进一步分为点运算、局部运算和全局运算。
(2)特征级图像处理
特征级处理是在像素图像产生的一系列特征上进行的操作。常用的特征包括:形状特征、纹理特征、梯度特征和三维特征等,一般采用统一的测度,如:均值、方差等,来进行描述和处理,具有在特征域内进行并行处理的可能性。但是,由于其特征具有象征意义和非局部特性,在局部区域并行的基础上,需要对总体进行处理。利用GPU实现并行化处理的难度比较大。
(3)目标级图像处理
目标级处理是对由一系列特征产生的目标进行操作。由于目标信息具有象征意义和复杂性,通常是利用相关知识进行推理,得到对图像的描述、理解、解释以及识别。由于其数据之间相关性强,且算法涉及到较多的知识和人工干预,并行处理的难度也比较大。
由此可见,整个图像处理的结构可以利用一个金字塔模型来表示。在底层,虽然处理的数据量巨大,但由于局部数据之间的相关性小,且较少的涉及知识推理和人工干预,因此大多数算法的并行化程度比较高。当沿着这个金字塔结构向高层移动时,随着抽象程度的提高,大量原始数据减少,所需的知识和算法的复杂性逐层提高,并行化处理的难度也逐渐加大。
由于绝大部分的图像处理算法是在像素级进行的,且GPU的SIMD并行流式处理在进行像素级的图像处理时具有明显的优势,而特征级和目标级处理无论是从数据的表达还是从算法自身的实现来说,都很难实现GPU并行化。因此,本文重点研究各种像素级图像处理操作的GPU并行化实现方法。
数字图像GPU并行化处理的基本流程与关键技术
现代GPU提供了顶点处理器和片段处理器两个可编程并行处理部件。在利用GPU执行图像处理等通用计算任务时,要做的主要工作是把待求解的任务映射到GPU支持的图形绘制流水线上。通常的方法是把计算任务的输入数据用顶点的位置、颜色、法向量等属性或者纹理等图形绘制要素来表达,而相应的处理算法则被分解为一系列的执行步骤,并改写为GPU的顶点处理程序或片段处理程序,然后,调用3D API执行图形绘制操作,调用片段程序进行处理;最后,保存在帧缓存中的绘制结果就是算法的输出数据,如图1所示[5][6]。
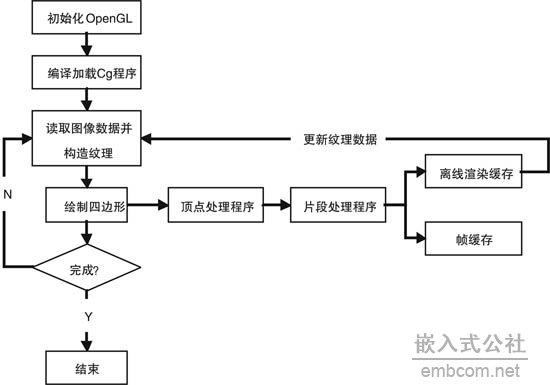
图1 遥感影像GPU并行化处理基本流程
虽然数字图像处理算法多种多样,具体实现过程也很不相同,但是在利用GPU进行并行化处理时,有一些共性的关键技术问题需要解决,如:数据的加载,计算结果的反馈、保存等。下面对这些共性的问题进行分析,并提出相应的解决思路。
数据加载
在GPU的流式编程模型中,所有的数据都必须以“流”的形式进行加载处理,并通过抽象的3D API进行访问。在利用 #p#page_title#e#GPU进行图像处理时,最直接有效的数据加载方法是把待处理的图像打包为纹理,在绘制四边形时进行加载、处理。同时为了保证GPU上片段程序能够逐像素的对纹理图像进行处理,必须将投影变换设置为正交投影,视点变换的视区与纹理大小相同,使得光栅化后的每个片段(fragment)和每个纹理单元(texel)一一对应。
对于图像处理算法中的其他参数,如果数据量很小,则可以直接通过接口函数进行设置;如果参数比较多,也应该将其打包为纹理的形式传输给GPU。在打包的过程中应充分利用纹理图像所具有的R、G、B、A四个通道。
计算结果的反馈、保存
应用程序是通过调用3D API绘制带纹理的四边形,激活GPU上的片段程序进行图像处理的,而GPU片段着色器的直接渲染输出是一个帧缓冲区,它对应着计算机屏幕上的一个窗口,传统上用来容纳要显示到屏幕的像素,但是在GPU流式计算中可以用来保存计算结果。虽然CPU可以通过3D API直接读写这个帧缓冲区,将渲染处理的结果从帧缓存中复制到系统内存进行保存,但是帧缓存的大小受窗口大小限制,而且由于AGP总线的带宽限制(2.1GB/s),从显存到系统内存的数据回读操作效率低下。对于大幅影像的处理应用是显然不适合的,特别是在中间计算结果的保存反馈时,采用帧缓存方式将成为制约GPU性能发挥的最主要瓶颈。
针对以上问题,笔者利用离线渲染缓存Pbuffer作为输出缓存。Pbuffer是OpenGL1.3版本的WGL_ARB_pbuffer扩展提供的输出缓存,它通过在显存中开辟一个不可见的数据缓冲区,取代帧缓存来保存片段处理器的输出结果。如果这个结果只是中间计算数据,还可以采用渲染到纹理的技术,把Pbuffer中的数据绑定到一个纹理,供下一遍绘制的片段程序取用,减少数据在显存和系统内存之间的传输,实现整个数据流在GPU芯片内部的流转,显著提高数据的反馈速度。特别是在需要GPU反复执行的情况下,可以构造两个Pbuffer,交替的作为输入或输出纹理使用,产生所谓的“Ping-Pong”方法,有效避免中间计算结果的回读操作。
图像卷积运算的GPU并行化试验
卷积运算是一种常见的数字图像处理局部运算,通过选择不同的卷积核,可以实现不同的图像处理效果。图像卷积运算定义为:
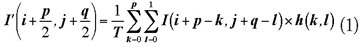
式中,为卷积运算以后的图像;为待处理的图像;为卷积核;T为常数,当卷积核中所有系数之和不为零时,T等于所有系数之和,否则等于1。
试验平台与数据
硬件平台为: Intel Core 2 2.0GHz CPU,1GB系统内存,NVIDIA公司的GeForce G0 7400 GPU, 512MB显存。
软件平台:Windows XP操作系统,CPU程序开发环境为Microsoft Visual C++2005,三维绘制接口为OpenGL及其扩展库WGL_ARB_pbuffer,GPU程序开发语言为Cg。
所采用的试验数据有两组,如图2所示:
第一组为:截取的新加坡部分地区QucikBird卫星影像,大小为(像素);
第二组为:截取的黄河小浪底部分地区Spot4卫星影像,大小为(像素)。

(a)试验数据一

(b)试验数据二
图2 卷积运算试验数据
试验步骤与数据记录
为了进行多组数据的对比试验,首先对原始图像数据进行预处理,通过裁减获得大小分别为2048×2048、1024×1024、521×512、256×256、128×128的试验数据。
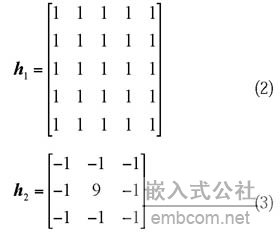
以经过预处理的10幅不同大小的图像进行卷积运算对比试验,分别运行卷积平滑和卷积锐化的CPU和GPU程序,并记录处理时间。试验所用的平滑卷积核h1为式(2),锐化卷积核h2为式(3):
试验结果与分析
图3所示为图像数据二512×512的平滑和锐化试验的处理结果,图4为GPU加速效率对比图。

(a)卷积平滑后图像

(b)卷积锐化后图像
图3 数据二的图像平滑、锐化效果对比
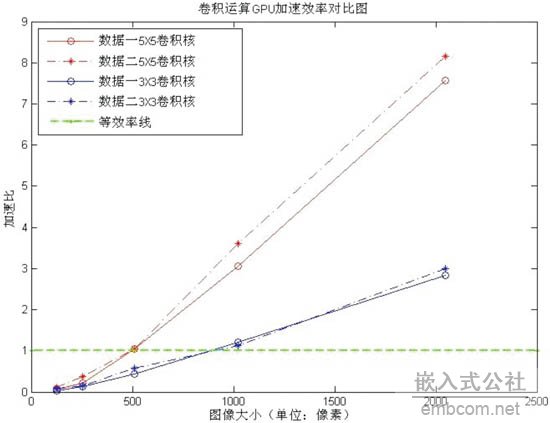
图4 卷积运算GPU加速效率对比图 #p#page_title#e#
从图4可以看出:随着图像的增大,特别是卷积核的变大,GPU的加速效果更加明显,例如:对2048×2048大小的图像进行5×5的卷积运算,最高加速比达到了8倍多。但是,在图像数据较小时,由于OpenGL的初始化和纹理数据的加载耗费了大量的时间,使得GPU并行处理的优势消失,甚至还没有CPU处理的速度快。
结语
本文对GPU的并行性和数字图像处理算法的并行层次进行了简要的介绍,提出了像素级图像处理的GPU并行化实现方法,并对其基本流程和关键技术:数据的加载,计算结果的反馈与保存等问题进行了详细论述,最后通过图像的平滑和锐化的卷积运算证明了GPU在数字图像并行化处理方面的强大优势。
参考文献:
[1] 柳有权.基于物理的计算机动画及其加速技术的研究[D].北京:中国科学院研究生院博士论文,2005.
[2] 谭久宏、周维超、吴钦章.基于GPU的数字图像处理[J].科教文汇,2006,4:178-179.
[3] 卢丽君、廖明生、张路.分布式并行计算技术在遥感数据处理中的应用[J].测绘信息与工程,2005,30(3):1-3.
[4] DOWNTON A, CROOKES D. Parallel Architectures for Image Processing [J]. Electronics and Communication Engineering Journal, 1998, 10(3):139-151.
[5] 龚敏敏.GPU精粹2—高性能图形芯片和通用计算编程技巧(译)[M].北京:清华大学出版社,2007.
[6] 洪伟、刘亚妮、李骑、丁莲珍.Cg教程—可编程实时图形权威指南(译)[M].北京:人民邮电出版社,2004:7-10.
[7] 吴恩华.图形处理器用于通用计算的技术、现状及其挑战[J].软件学报,2004,15(10):1493-1504


